
# 快速入门
![]()
![]()
本指南将向您展示如何通过几个简单的步骤启动集群、导入数据并执行 SQL 查询。有关其他开发者工具(如Python 客户端)的更多信息,请参阅开发者工具部分。
# 如何启动您的第一个集群
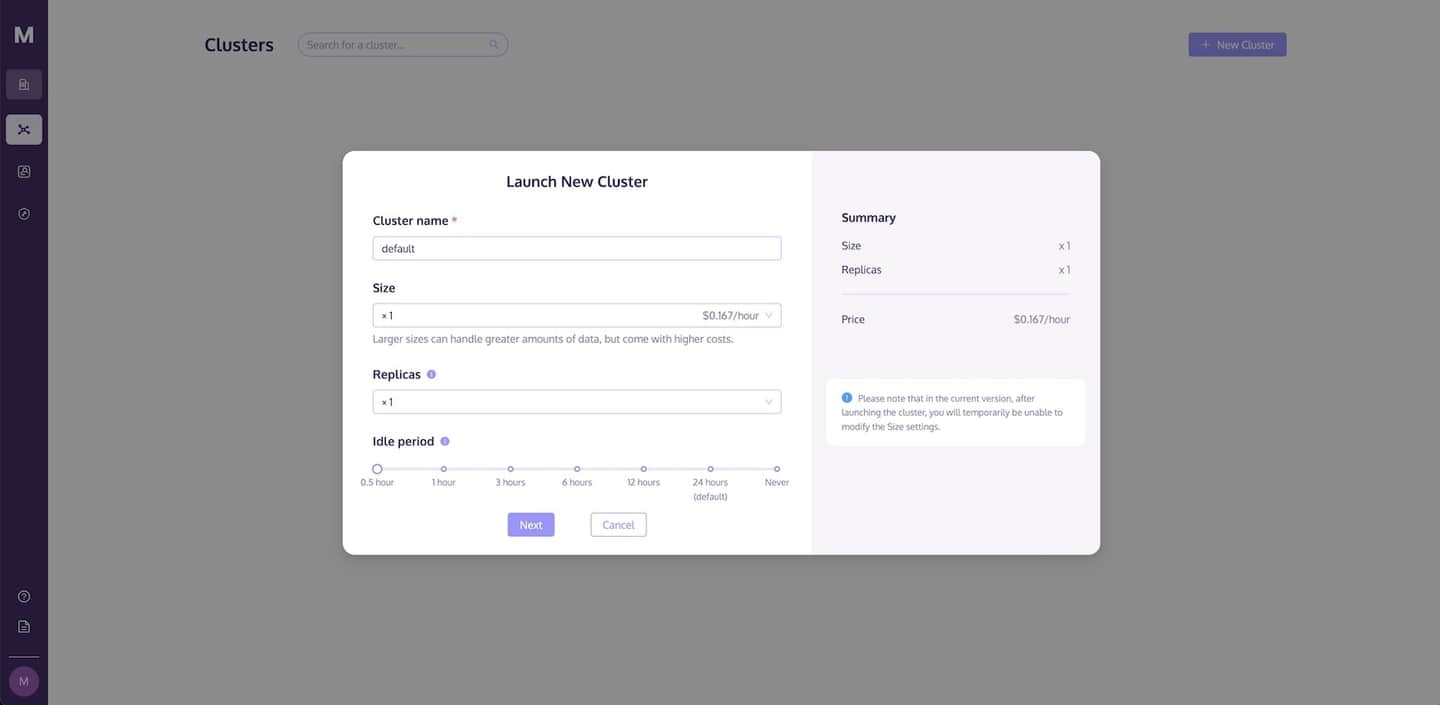
在执行任何数据操作之前,您需要启动一个集群。集群页面允许您创建一个集群并配置计算和存储资源以满足您的需求。
按照以下步骤启动一个新的集群:
- 转到集群页面,单击**+新建集群**按钮启动一个新的集群。
- 给您的集群命名。
- 单击启动以运行集群。
提示
MyScale 的开发层级限制为默认配置,并不支持多个副本。请参阅更改计费计划部分,并升级到标准计划以获得更强大的配置。
# 环境设置
您可以使用以下开发者工具之一连接到 MyScale 数据库:
不过,让我们从 Python 开始。
# 使用 Python
在开始使用 Python 之前,您需要安装ClickHouse 客户端 (opens new window),如下面的 shell 脚本所述:
pip install clickhouse-connect
安装成功 ClickHouse 客户端后,下一步是通过提供以下详细信息从 Python 应用程序连接到您的 MyScale 集群:
- 集群主机
- 用户名
- 密码
要查找这些详细信息,请导航到 MyScale 集群页面,单击操作下拉链接,然后选择连接详细信息。
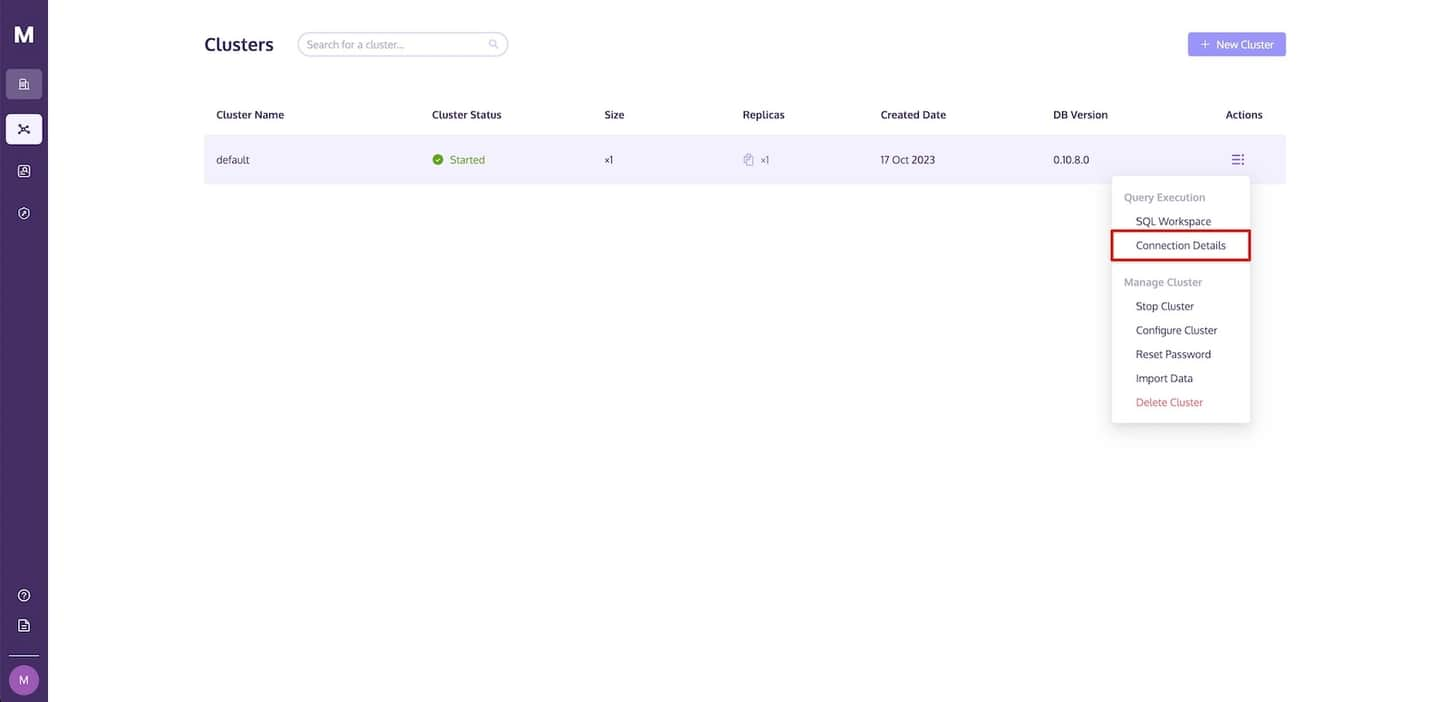
如下图所示,将显示一个连接详细信息对话框,其中包含访问 MyScale 所需的必要代码。单击复制图标将相应的代码复制并粘贴到您的 Python 应用程序中。
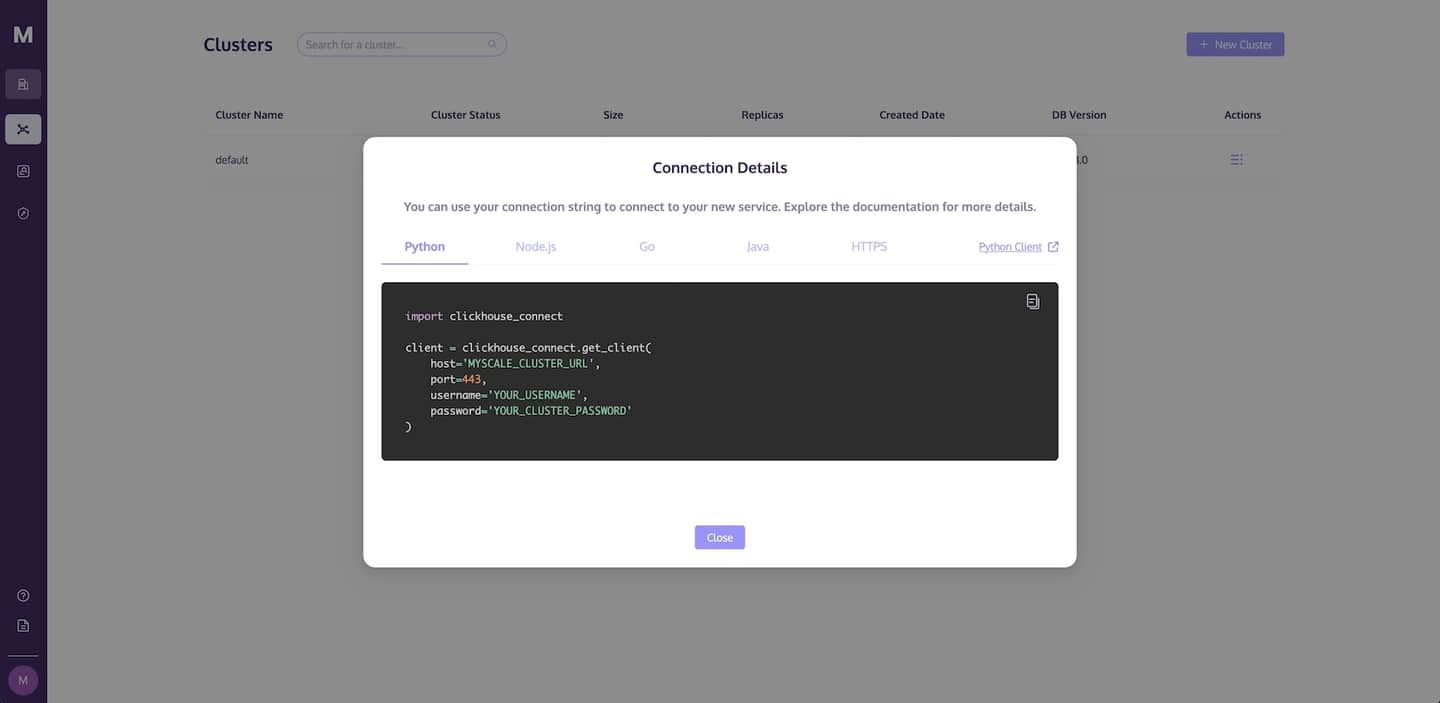
提示
有关连接到 MyScale 集群的更多信息,请参阅连接详细信息。
# 使用 MyScale 控制台
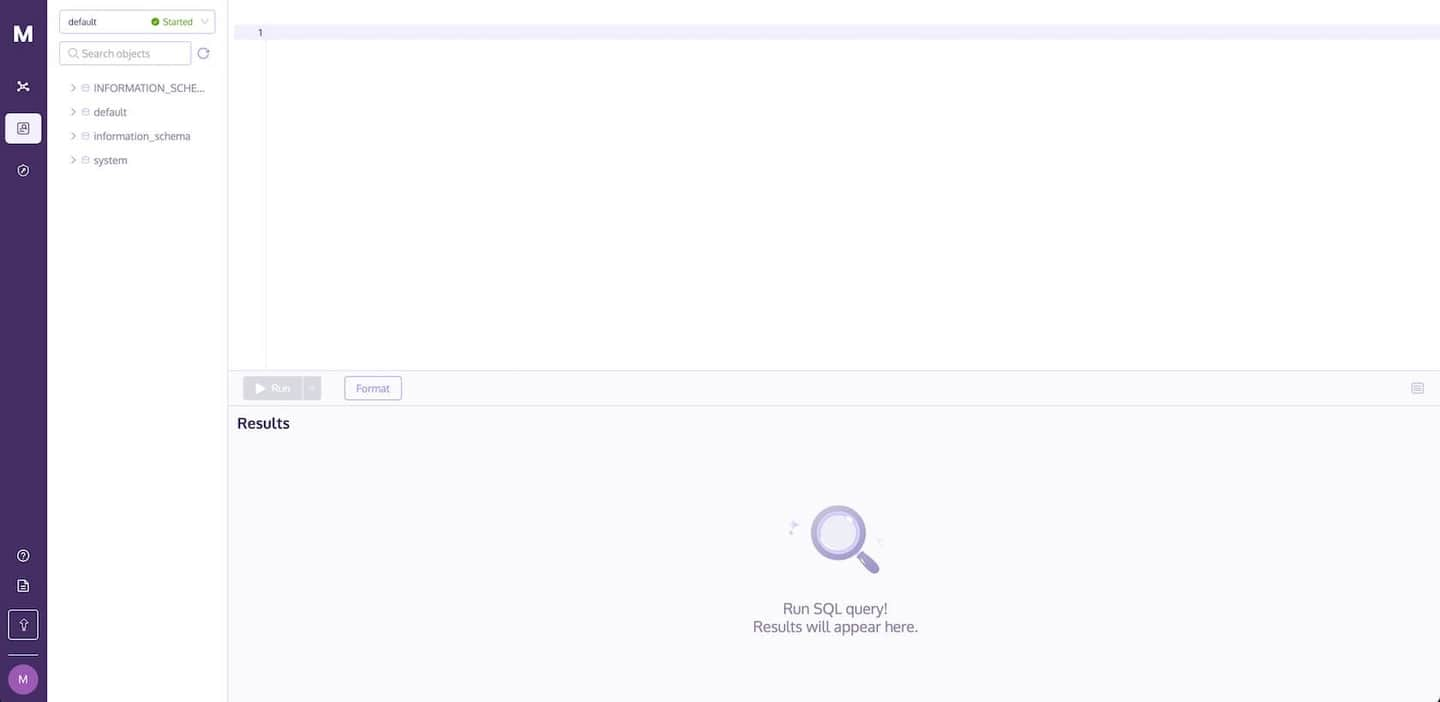
要使用 MyScale 控制台导入数据到您的数据库并运行查询,请导航到SQL 工作区页面。您的集群将自动选择,如下所示:
# 如何将数据导入数据库
按照以下步骤将数据导入 MyScale:
# 创建表
在导入任何数据之前,必须在 MyScale 中创建一个数据库表。
使用以下代码示例,让我们编写一个 SQL 语句(在 Python 和 SQL 中都有)来创建一个名为 default.myscale_categorical_search 的新表。
- Python
- SQL
# 创建一个具有 128 维向量的表。
client.command("""
CREATE TABLE default.myscale_categorical_search
(
id UInt32,
data Array(Float32),
CONSTRAINT check_length CHECK length(data) = 128,
date Date,
label Enum8('person' = 1, 'building' = 2, 'animal' = 3)
)
ORDER BY id""")
# 将数据插入表中
提示
MyScale 支持使用 s3 兼容的 API 从 Amazon S3 和其他云服务导入数据。有关从 Amazon S3 导入数据的更多信息,请参阅s3 表函数。
如下面的代码片段所示,让我们使用 SQL 将数据导入 default.myscale_categorical_search 表中。
支持的文件格式包括:
CSV(opens new window)CSVWithNames(opens new window)JSONEachRow(opens new window)Parquet(opens new window)
提示
有关所有支持的格式的详细说明,请参阅输入和输出数据的格式 (opens new window)。
- Python
- SQL
client.command("""
INSERT INTO default.myscale_categorical_search
SELECT * FROM s3(
'https://d3lhz231q7ogjd.cloudfront.net/sample-datasets/quick-start/categorical-search.csv',
'CSVWithNames',
'id UInt32, data Array(Float32), date Date, label Enum8(''person'' = 1, ''building'' = 2, ''animal'' = 3)'
)""")
# 构建向量索引
除了在结构化数据上创建传统索引外,您还可以在 MyScale 中为向量嵌入创建向量索引。按照以下逐步指南进行操作:
# 创建 MSTG 向量索引
如下面的代码片段所示,第一步是创建一个 MSTG 向量索引,即使用我们专有算法 MSTG 的向量索引。
- Python
- SQL
client.command("""
ALTER TABLE default.myscale_categorical_search
ADD VECTOR INDEX categorical_vector_idx data
TYPE MSTG
""")
提示
索引的构建时间取决于数据导入的大小。
# 检查向量索引构建状态
以下代码片段描述了如何使用 SQL 检查向量索引的构建状态。
- Python
- SQL
# 查询 'vector_indices' 系统表以检查索引创建的状态。
get_index_status="SELECT status FROM system.vector_indices WHERE table='myscale_categorical_search'"
# 打印索引创建的状态。如果索引创建成功,状态将为 'Built'。
print(f"index build status is {client.command(get_index_status)}")
以下是示例的输出结果:
- Python
- SQL
index build status is Built
提示
有关向量索引的更多信息,请参阅向量搜索。
# 执行 SQL 查询
在将数据导入 MyScale 表并构建向量索引后,您可以使用以下搜索类型查询数据:
提示
构建 MSTG 向量索引的最大优势是其快速的搜索速度。
# 向量搜索
传统上,我们会查询文本或图像,例如“蓝色的汽车”或蓝色汽车的图像。然而,MyScale 将所有查询都视为向量,并根据查询与表中现有数据之间的相似度(“距离”)返回查询的响应。
使用以下代码片段使用向量作为查询来检索数据:
- Python
- SQL
# 从表中随机选择一行作为目标
random_row = client.query("SELECT * FROM default.myscale_categorical_search ORDER BY rand() LIMIT 1")
assert random_row.row_count == 1
target_row_id = random_row.first_item["id"]
target_row_label = random_row.first_item["label"]
target_row_date = random_row.first_item["date"]
target_row_data = random_row.first_item["data"]
print("currently selected item id={}, label={}, date={}".format(target_row_id, target_row_label, target_row_date))
# 获取查询结果。
result = client.query(f"""
SELECT id, date, label,
distance(data, {target_row_data}) as dist FROM default.myscale_categorical_search ORDER BY dist LIMIT 10
""")
# 遍历查询结果的行,并打印每行的 'id'、'date'、'label' 和距离。
print("Top 10 candidates:")
for row in result.named_results():
print(row["id"], row["date"], row["label"], row["dist"])
包含十个最相似结果的结果集如下所示:
| id | date | label | dist |
|---|---|---|---|
| 0 | 2030-09-26 | person | 0 |
| 2 | 1975-10-07 | animal | 60,088 |
| 395,686 | 1975-05-04 | animal | 70,682 |
| 203,483 | 1982-11-28 | building | 72,585 |
| 597,767 | 2020-09-10 | building | 72,743 |
| 794,777 | 2015-04-03 | person | 74,797 |
| 591,738 | 2008-07-15 | person | 75,256 |
| 209,719 | 1978-06-13 | building | 76,462 |
| 608,767 | 1970-12-19 | building | 79,107 |
| 591,816 | 1995-03-20 | building | 79,390 |
提示
这些结果是向量嵌入,您可以通过引用结果的 id 来检索原始数据。
# 过滤搜索
我们不仅可以使用向量搜索(使用向量嵌入)查询数据,还可以使用结构化数据和向量数据的组合执行 SQL 查询,如下面的代码片段所示:
- Python
- SQL
# 获取查询结果。
result = client.query(f"""
SELECT id, date, label,
distance(data, {target_row_data}) as dist
FROM default.myscale_categorical_search WHERE toYear(date) >= 2000 AND label = 'animal'
ORDER BY dist LIMIT 10
""")
# 遍历查询结果的行,并打印每行的 'id'、'date'、'label' 和距离。
for row in result.named_results():
print(row["id"], row["date"], row["label"], row["dist"])
包含十个最相似结果的结果集如下所示:
| id | date | label | dist |
|---|---|---|---|
| 601,326 | 2001-05-09 | animal | 83,481 |
| 406,181 | 2004-12-18 | animal | 93,655 |
| 13,369 | 2003-01-31 | animal | 95,158 |
| 209,834 | 2031-01-24 | animal | 97,258 |
| 10,216 | 2011-08-02 | animal | 103,297 |
| 605,180 | 2009-04-20 | animal | 103,839 |
| 21,768 | 2021-01-27 | animal | 105,764 |
| 1,988 | 2000-03-02 | animal | 107,305 |
| 598,464 | 2003-01-06 | animal | 109,670 |
| 200,525 | 2024-11-06 | animal | 110,029 |
 京公网安备 11010802042981号
京公网安备 11010802042981号