
In our previous exploration of Contrastive Learning (opens new window), we uncovered how models can learn to differentiate between similar and dissimilar data by bringing like items closer and pushing unlike ones apart in an embedding space. We discussed methods like SimCLR (opens new window), MoCo (opens new window), and CLIP (opens new window), which have significantly advanced self-supervised learning (opens new window).
Continuing this journey into metric learning, let’s talk about Triplet Loss. It builds upon the principles of contrastive learning and plays a crucial role in tasks that require fine-grained distinctions, such as face recognition, image retrieval, and signature verification.
# Metric Learning
Before we dive into Triplet Loss, it's important to understand Metric Learning. Metric learning is a type of machine learning that focuses on learning a distance function (or metric) that measures similarity between data points. The core idea is simple:
- Similar data points should be close together in the embedding space.
- Dissimilar data points should be far apart.
We use a machine learning model to generate embeddings, then train the model to minimize the distance between similar data points while maximizing the distance between data points that belong to different categories or labels.
# Common distance metrics
As we talk about the distance, the choice of distance is up to the user. It can be Euclidean, Manhattan or some advanced distance measures. Some commonly used distances are:
- Minkowski Distance – Minkowski is a generalization of norm-based distances by calculating p-norm, where
- Cosine Similarity – Cosine similarity is based on the dot product of vectors. It takes into account that parallel vectors have similarity of 1 (cos 0º), perpendicular of 0 (cos 90º) while opposite have -1 (cos 180º) between them.
- Manhattan Distance: Also known as the city block or L1 distance, Manhattan distance calculates the sum of the absolute differences between the coordinates of two points. It is particularly useful when dealing with grid-like paths or in situations where diagonal movement is not possible.
- Jaccard Distance – Jaccard distance measures the similarity (or dissimilarity) between two groups (sets) by taking the ratio of their matching elements vs their total elements.
- Mahalanobis Distance – Mahalanobis distance is a unique measure which accounts for the distribution in the data. It is defined as:
Here
# What is Triplet loss?
Now lets come back to the main topic. Triplet loss works on a simple principle. We pick a point in the embedding space (usually called anchor) with a positive and negative point respectively. Inevitably, we want to maximize the distance with the negative points and minimize them for the positive ones.
Here
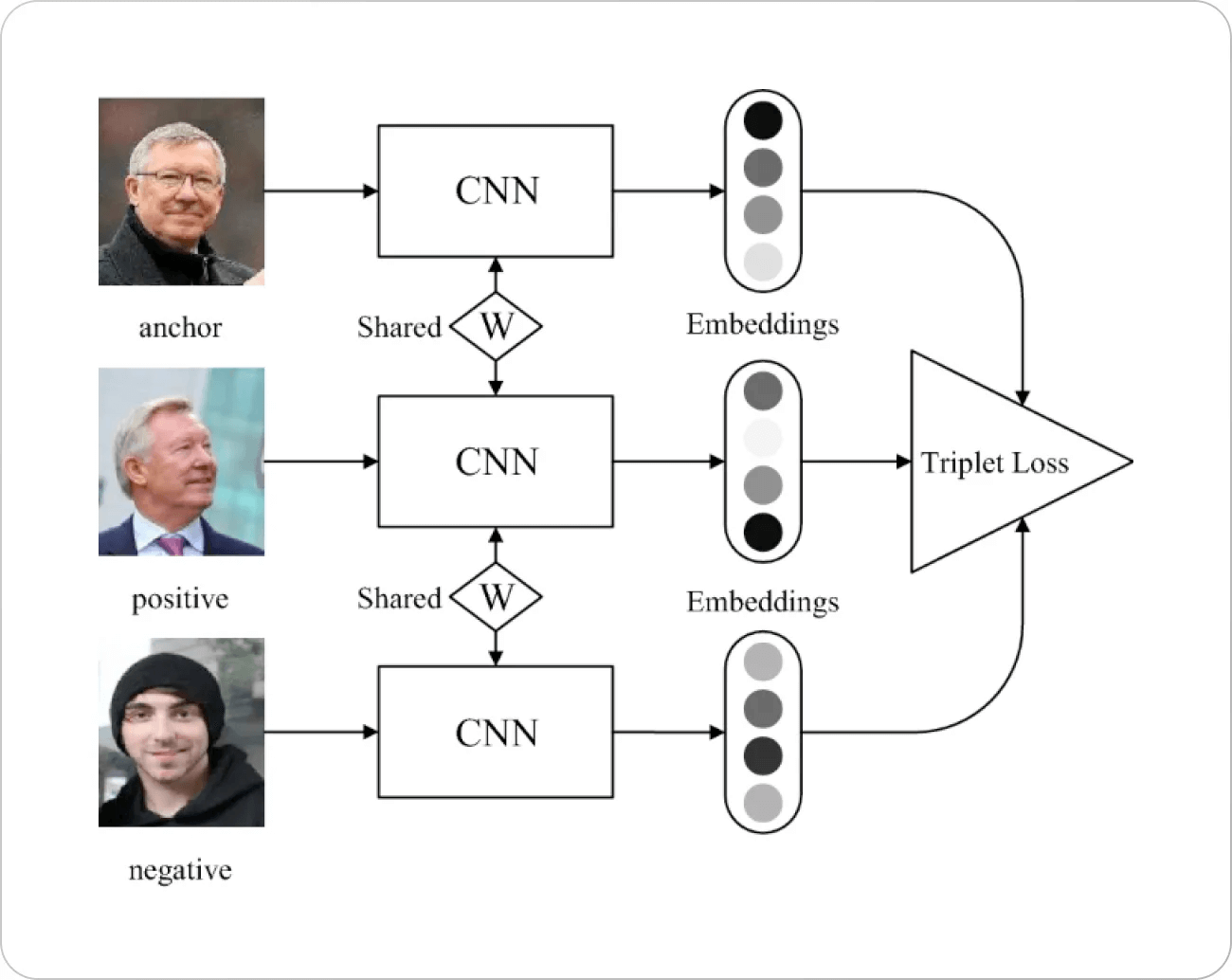
Image Source: Springer Paper
There is some background behind Triplet loss’s motivation. One of the earlier loss functions for face recognition (mainly based on the
# How Triplet Loss Works
Imagine plotting data points in an embedding space. With Triplet Loss:
- Anchors and positives (same class) are pulled closer together.
- Anchors and negatives (different classes) are pushed apart.
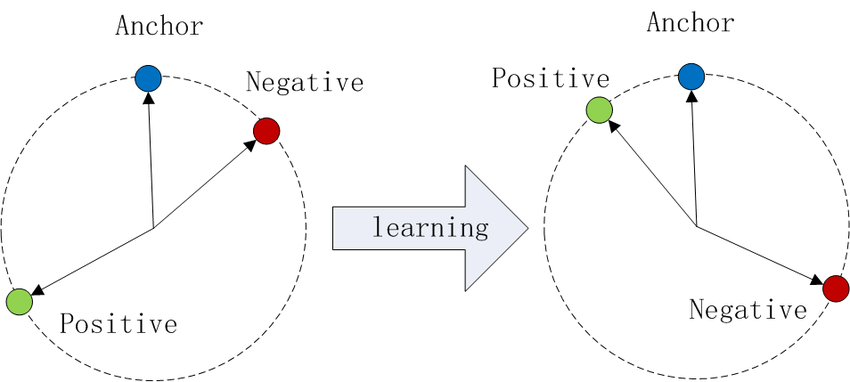
Image Source: Wikipedia
This process creates distinct clusters for each class, improving the model's ability to distinguish between them.
# The Role of Margin α
The margin α is a hyperparameter that sets the minimum desired distance between positive and negative pairs relative to the anchor. It prevents the model from collapsing all embeddings to the same point and encourages a meaningful separation between classes.
- Too small
α - Too large
α
Selecting an appropriate margin is crucial for effective training.
# Why Use Triplet Loss?
Triplet Loss is particularly useful when:
- Fine-grained distinctions are important: In tasks like face recognition, where subtle differences must be captured.
- Class distributions are imbalanced: It focuses on relative distances rather than absolute positions in the embedding space.
- Learning discriminative features: It forces the model to pay attention to features that differentiate between classes.
# Triplets Mining
Triplet loss definitely comes at a cost as we need to compare every point with all the positive and negative points, which means training is infeasible as training data grows, leading to worst-case complexity of
To address this, a smart use of finding hard positives and hard negatives is made. For example, in face recognition, a hard positive can be pictures of same person but in quite different settings (like lighting, dress, pose, etc.) and similarly, hard negatives can be different people in the similar settings. The process of finding these hard positives and hard negatives is know as mining. Similar to other algorithms involving a lot of data, it is also done in minibatches.
# Challenges
Finding these hard positives and negatives is a definite problem, but even bigger challenges arise later on in the training.
- Choosing the right batch size: Having too little examples leads to a poor representation of data and hence inefficient hard examples. On the other hand, having too big batch sizes lead to computational resources limitations (GPU memory limits mainly).
- Degree of hardness: Presenting the hard examples, especially hard negatives first up leads to poor training [1] and its quite understandable. As a result, some negative examples are searched so that
In other words, we pick the negative samples,
Note:
Curriculum learning’s concept is quite relevant to picking the right degree of hardness. This technique, as its name depicts, is inspired from learning in a school. Using this technique, we present the model with the easiest examples first (like black and white contrasting samples) and gradually up the ante. Anti-curriculum learning goes in reverse by presenting the toughest examples first and loosen up gradually. In 2021, researchers [3] done an extensive study to find out curriculum learning can be helpful in some cases, especially with noisy data and limited training time.
- To (generate) online or not to online: Another choice is whether to generate all the triplets in advance (offline) or generate them dynamically. Both options have their own merits and demerits. Offline generation allows us to generate batches normally, while online generation is adapative. There might be an overhead for generating hard examples on the other hand.
# Triplet Loss and Contrastive Learning
Both triplet loss and contrastive learning are aimed at learning by keeping embeddings closer to the desired class (i.e. smaller distances) and farther from the outliers, so often they are disguised as same. While their purpose is same, yet there is a clear difference as contrastive loss contrasts each sample with a batch of positive and negative samples, while triplet loss does it (theoretically) for all the possible triplets.
Since contrastive learning doesn’t need to make all the triplets (or pairs), its computationally much faster than the triplet loss’ implementations. Triplet loss on the other hand has a better accuracy in most of the cases.
# Difference Between Contrastive learning and Triplet loss
Data Grouping:
- Contrastive Learning: Operates on pairs of samples (positive or negative pairs).
- Triplet Loss: Operates on triplets of samples (anchor, positive, negative).
Loss Mechanism:
- Contrastive Learning: Uses a binary decision on whether pairs are similar or dissimilar.
- Triplet Loss: Focuses on relative distances between anchor-positive and anchor-negative pairs, ensuring that positive examples are closer to the anchor than negative examples.
Flexibility:
- Contrastive Learning: Simpler in terms of computation, as it only involves pairs, but it can be less effective in complex cases where multiple negative examples are close to the anchor.
- Triplet Loss: More complex but provides better control over the embedding space because it directly optimizes the relative distances.
Training Complexity:
- Contrastive Learning: Generally less complex to implement since only pairs are needed.
- Triplet Loss: More complex since it requires carefully selected triplets (hard negatives are often used to increase performance).
# Implementation
We can implement it by taking the anchor (reference point) with positive and negative samples. Here, we will use the Minkowski distance – i.e. leave the choice of the norm’s order on the user.
import torch
import torch.nn as nn
class TripletLoss(nn.Module):
def __init__(self, margin=1.0):
super(TripletLoss, self).__init__()
self.margin = margin
def forward(self, anchor, positive, negative, norm_order):
pos_dist = torch.norm(anchor - positive, p=norm_order, dim=1)
neg_dist = torch.norm(anchor - negative, p=norm_order, dim=1)
loss = torch.mean(torch.clamp(pos_dist - neg_dist + self.margin, min=0.0))
return loss
# Best Practices
Some of the best practices for using triplet loss are:
- Normal Euclidean distance has better results than the squared Euclidean.
- Normalization (like Batch or Layer normalization) usually doesn’t help in training.
- An optimum batch size ([1] used around 1800 in most of the experiments).

# Conclusion
Triplet Loss is a valuable tool in metric learning that helps models differentiate between similar and dissimilar data points by focusing on their relative distances. Building on the ideas behind contrastive learning, it is especially useful for tasks that require subtle distinctions between classes.
By incorporating Triplet Loss into our models, we gain the ability to teach them to recognize patterns in a more refined way, opening up exciting possibilities for applications in fields like computer vision, language processing, and much more.
# References
- Schroff, et al (CVPR 2015) FaceNet: A Unified Embedding for Face Recognition and Clustering
- Hermans, et al (2017), In Defense of the Triplet Loss for Person Re-Identification
- Wu, et al. (ICLR 2021), When Do Curricula Work?



