
As one of our earlier blog posts explored (opens new window), vector search significantly advances information retrieval with a more nuanced and contextually aware approach than traditional keyword matching. Transforming text into numerical vectors aligns the contextual meaning of search queries with the data, thereby improving the relevance of search results.
However, challenges with vector search also occur—most notably the possible loss of information during text-to-vector transformations—requiring the adoption of additional methods to improve search accuracy.
What are these additional methods?
The brief answer to this question is that one of the most significant “additional methodology” is implementing a two-stage retrieval system when using vector search to retrieve information.
Let’s expand on this answer by diving into a step-by-step guide to implementing a two-stage retrieval methodology with MyScale, demonstrating how to combine vector search and reranking to optimize information retrieval systems efficiently and effectively.
# What is Reranking?
But first, let’s define reranking—and consider why it forms part of the two-stage retrieval process.
Succinctly stated, reranking reorders search results to increase a vector search’s contextual relevance. According to https://en.wiktionary.org/wiki/reranking (opens new window), it is “the act of ranking something again or differently... [For example,] the algorithm performs several rerankings before reaching the optimal result.”
Reranking, often implemented with a cross-encoder model (opens new window), augments the search results by providing a more refined set of results. Unlike the initial vector search—summarizing documents into vectors before querying these documents—reranking processes the query and documents together, reordering the search results with greater precision based on relevance.
However, as with everything, there are challenges when utilizing reranking—the most significant being its high computation demand and subsequent impracticality when processing large datasets, substantially restricting its standalone application potential.
# The Two-Stage Retrieval System
To address these challenges, a two-stage retrieval system was developed—combining the strengths of vector search and reranking, beginning with a vector search for an initial broad-sweep result set and then selectively applying reranking for greater accuracy.
# MyScale's Two-Stage Retrieval System
MyScale’s two-stage retrieval system starts with a vector search that scans the database, selecting a wide range of documents—all closely matching the search query’s semantics—and efficiently reducing the massively extensive dataset to a relevant subset.
Next: This subset is refined using a reranking function, carefully sorting it based on similarity scores, prioritizing precision, and aligning the final result set as close to the user’s intent as possible.
To streamline this two-stage retrieval system, we have integrated these reranking functions (opens new window) with MyScale—our vector database—making them accessible via a simple SQL query.
Note:
These functions utilize sophisticated reranking APIs, providing users with an easy-to-use interface for complex data sorting operations as well as condensing robust search functionality into a concise and efficient user experience.
As illustrated in the following diagram, users can initiate this two-stage retrieval mechanism with a straightforward command, incorporating a vector search subquery to return the top N documents and a reranking query to fine-tune this result set, extracting the most relevant K documents.
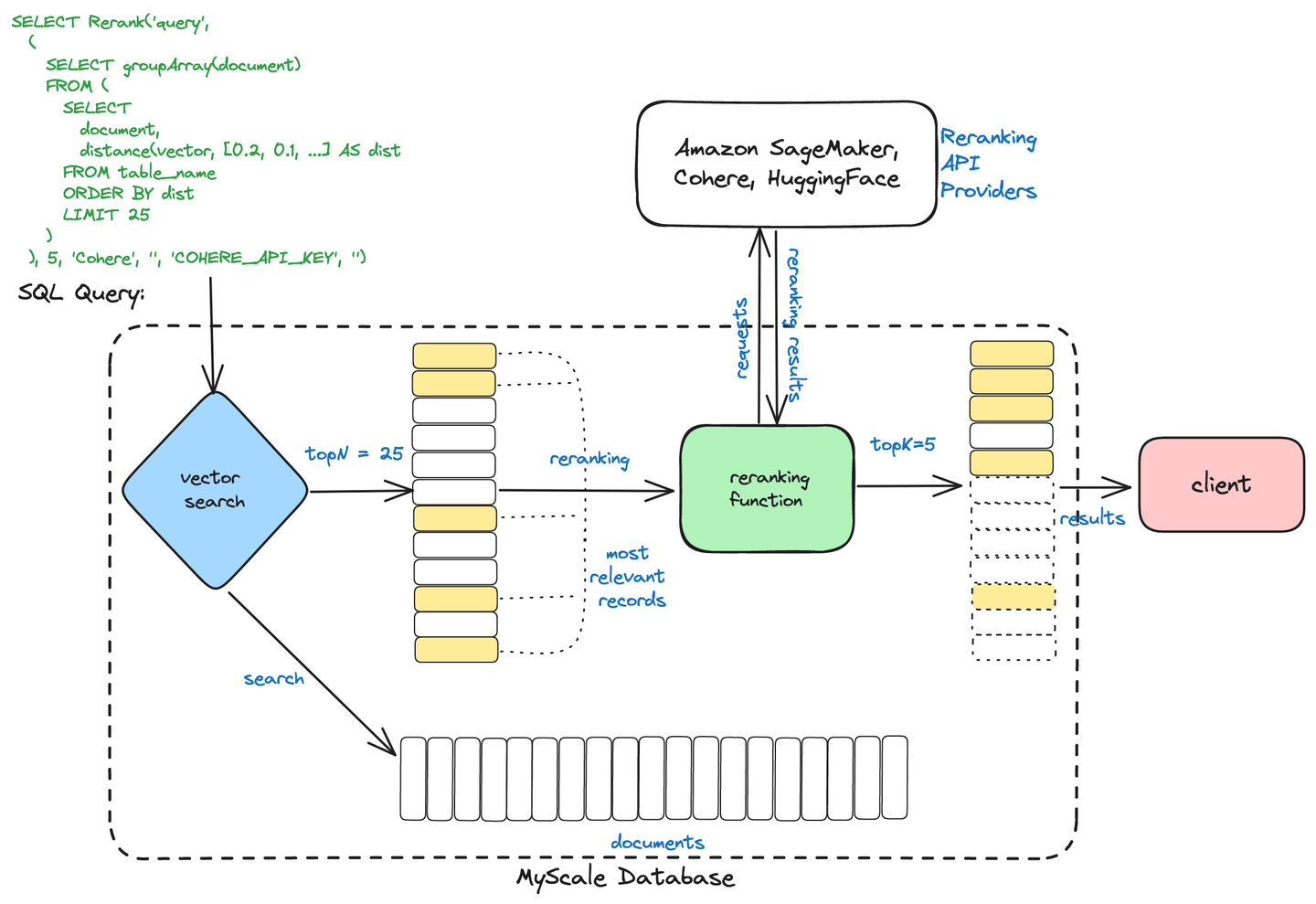
The effectiveness of this system is evident in its performance metrics. Using OpenAI Embeddings (opens new window) for analysis, we observed significant improvements in retrieval accuracy. The Hit Rate increased from 0.854545 to 0.895455 using the bge-reranker-base model. The Mean Reciprocal Rank—MRR—also rose from 0.640303 to 0.707652, demonstrating the method's proficiency in sourcing relevant search results. These improvements underscore the value of integrating reranking into the information retrieval process.
Note:
We've detailed our evaluation methodology and results in this notebook (opens new window), following the methods discussed in this blog (opens new window) by LlamaIndex.
# Implementing MyScale's Two-Stage Retrieval System
Let’s now work through a practical example to understand our two-stage retrieval system better, focusing on improving the Abstractive QA (opens new window) sample application with specifics outlined in MyScale’s documentation.
Note:
The only change required is to the original example's query phase (opens new window)—we're still using the same table and data.
The original Abstractive QA app transforms questions into embeddings using a separate retriever. Next, it executes a search query to find the top_k candidates. Now, as the following SQL statement shows, with MyScale’s embedding function, these steps are merged into a single SQL command.
SELECT summary,
distance(
summary_feature,
CohereEmbedText('what is the difference between bitcoin and traditional money?')
) AS dist
FROM default.myscale_llm_bitcoin_qa
WHERE article_rank < 500
ORDER BY dist LIMIT 10
This SQL statement uses a custom embedding function—CohereEmbedText—created with Cohere's embed-english-light-v3.0 model (opens new window)—defined in the following code snippet.
CREATE FUNCTION CohereEmbedText ON CLUSTER '{cluster}'
AS (x) -> EmbedText(
x,
'Cohere',
'',
'YOUR_COHERE_API_KEY',
'{"model":"embed-english-light-v3.0", "input_type":"search_query"}')
To further streamline the process, we introduce a custom reranking function as outlined in the function documentation (opens new window):
CREATE FUNCTION CohereRerank ON CLUSTER '{cluster}'
AS (x,y,z) -> Rerank(
x, y, z, 'Cohere', '', 'YOUR_COHERE_API_KEY', '');
With these functions in place, we can now implement the two-stage retrieval system using the following SQL statement:
SELECT
tupleElement(arrayElement, 2) AS summary,
tupleElement(arrayElement, 3) AS score
FROM (
SELECT arrayJoin(CohereRerank('what is the difference between bitcoin and traditional money?',
(SELECT groupArray(summary)
FROM (
SELECT summary, distance(summary_feature, CohereEmbedText('what is the difference between bitcoin and traditional money?')) as dist
FROM default.myscale_llm_bitcoin_qa
WHERE article_rank < 500
ORDER BY dist
LIMIT 50
)
), 10
)) AS arrayElement
)
This SQL statement comprises the following steps to implement our two-stage retrieval system:
- Expand the search results from 10 to 50 to avoid missing relevant information;
- Group the top 50 candidates into an array—for reranking—using groupArray (opens new window);
- Reorder these candidates based on relevance with the
CohereRerankfunction, extracting the top 10 most pertinent summaries; and finally - Use arrayJoin (opens new window) (for unfolding result set into multiple rows) and tupleElement (opens new window) (for extracting specified column from the result rows) to structure the results to improve user presentation.

# Conclusion
In summary, MyScale's two-stage retrieval system exemplifies the power of simplicity and efficiency in modern search technology. It demonstrates that even sophisticated processes like vector search combined with advanced reranking functions can be seamlessly executed with a single, straightforward SQL query. This approach not only makes complex retrieval processes accessible to a broader array of users but also highlights MyScale’s commitment to providing powerful—yet user-friendly—data search and analysis tools.



