
The rise of powerful large language models (LLMs) like GPT-4, Gemini 1.5 and Claude 3 has been a game-changer in AI and technology. With some models capable of processing over 1 million tokens (opens new window), their ability to handle long contexts is truly impressive. However:
- Many data structures are too complex and constantly evolving for LLMs to handle effectively on their own.
- Managing massive, heterogeneous enterprise data within a context window is simply impractical.
Retrieval-augmented generation (RAG) helps address these issues, but retrieval accuracy is a major bottleneck for end-to-end performance, and many vector databases don't scale well for complex use cases. One solution is integrating LLMs with big data through advanced SQL vector databases. This type of synergy between LLMs and big data not only makes LLMs more effective but also enables people to gain better intelligence from big data. Moreover, it further reduces model hallucination while providing data transparency and reliability.
# Current State of Vector Databases
As the cornerstone of RAG systems, vector databases have developed rapidly in the past year. They can generally be categorized into three types: dedicated vector databases, keyword and vector retrieval systems, and SQL vector databases. Each has advantages and limitations.
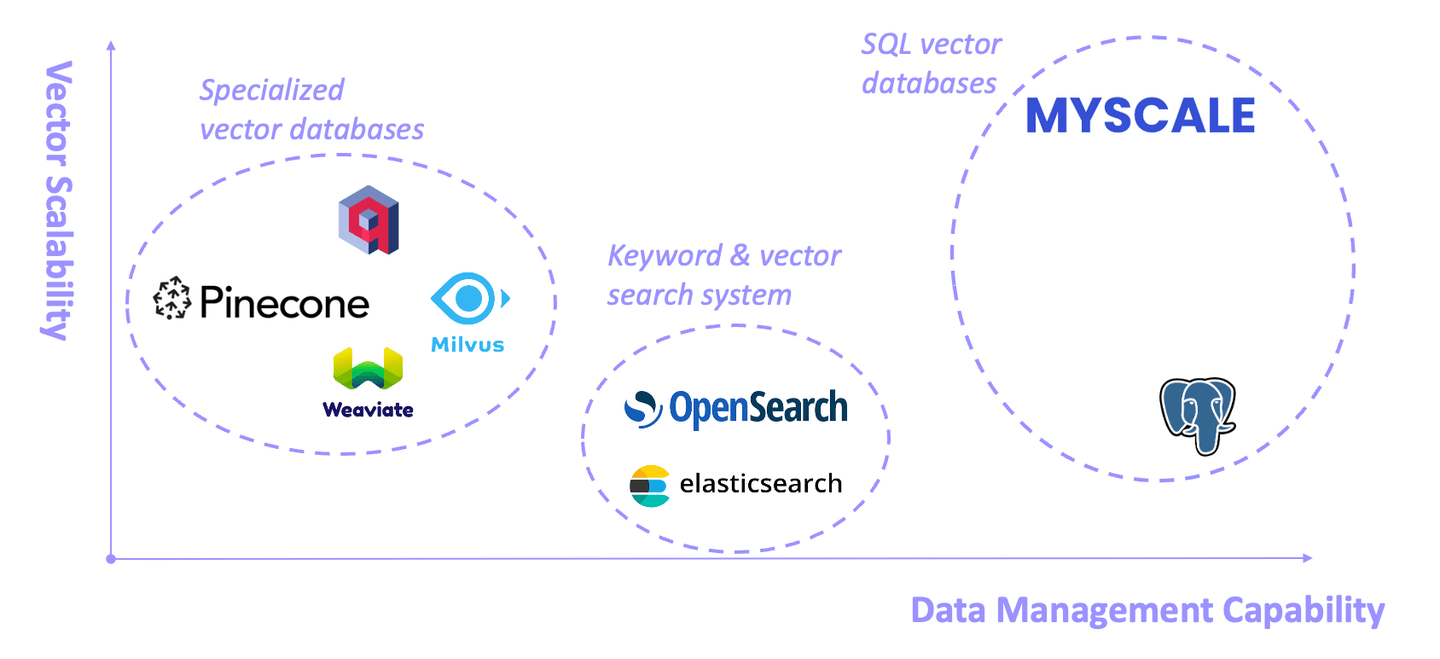
# Specialized Vector Databases
Some vector databases (like Pinecone, Weaviate and Milvus) are designed specifically for vector search from the outset. They exhibit good performance in this area but have somewhat limited general data management capabilities (opens new window).
# Keyword and Vector Retrieval Systems
Represented by Elasticsearch and OpenSearch, these systems are widely used in production due to their comprehensive keyword-based retrieval capabilities. However, they consume substantial system resources, and the accuracy and performance of keyword and vector hybrid queries are often unsatisfactory (opens new window).
# SQL Vector Databases
SQL vector database (opens new window) is a specialized type of database that combines the capabilities of traditional SQL databases with the abilities of a vector database. It provides you the ability to efficiently store and query high-dimensional vectors with the help of SQL.
Two major SQL vector databases are illustrated in the figure above: pgvector and MyScaleDB. pgvector is a vector search plugin for PostgreSQL. It is easy to get started with and useful for managing small data sets. However, due to Postgres’ row storage disadvantages and vector algorithm limitations, pgvector tends to have lower accuracy and performance for large-scale, complex vector queries.
MyScaleDB (opens new window) is an open source SQL vector database built on ClickHouse (a columnar storage SQL database). It is designed to provide a high-performance and cost-effective data foundation for GenAI applications. MyScaleDB is also the first SQL vector database to outperform specialized vector databases (opens new window) in overall performance and cost-effectiveness.
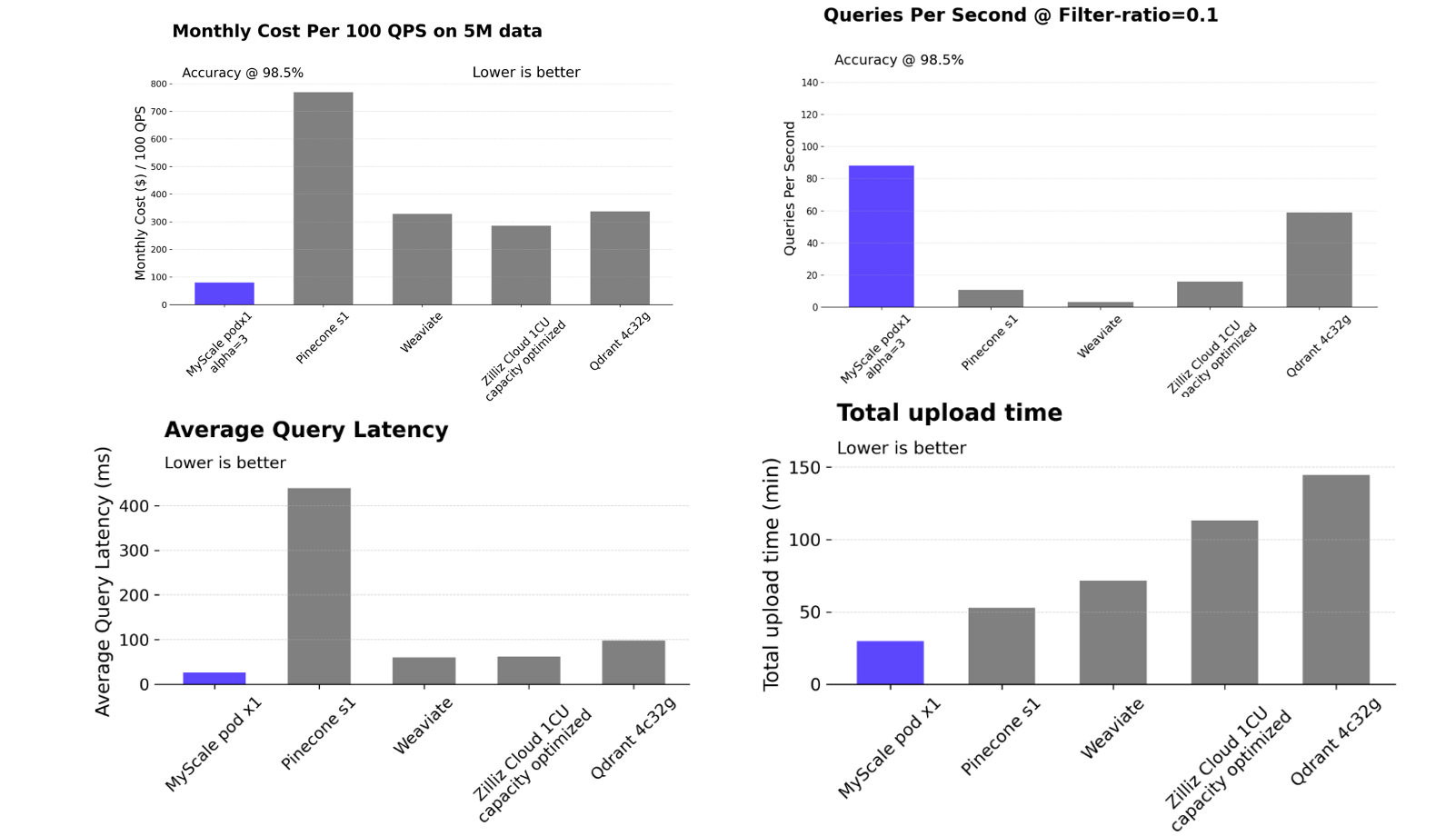
Source: https://myscale.github.io/benchmark (opens new window)
# The Power of SQL and Vector Joint Data Modeling
Despite the emergence of NoSQL and big data technologies, SQL databases continue to dominate the data management market half a century after SQL's inception. Even systems like Elasticsearch and Spark have added SQL interfaces. With SQL support, MyScaleDB, an SQL vector database, enables high performance in vector search and analytics (opens new window).
In real-world AI applications, integrating SQL and vectors enhances data modeling flexibility and simplifies development. For instance, a large-scale academic product uses MyScaleDB for intelligent Q&A over massive scientific literature data. The main SQL schema includes over 10 tables, several with vector and keyword-based inverted index structures, connected via primary and foreign keys. The system handles complex queries involving structured, vector and keyword data and joined queries across multiple tables. This is a challenging task for specialized vector databases, which often leads to slow iteration, inefficient querying and high maintenance costs.
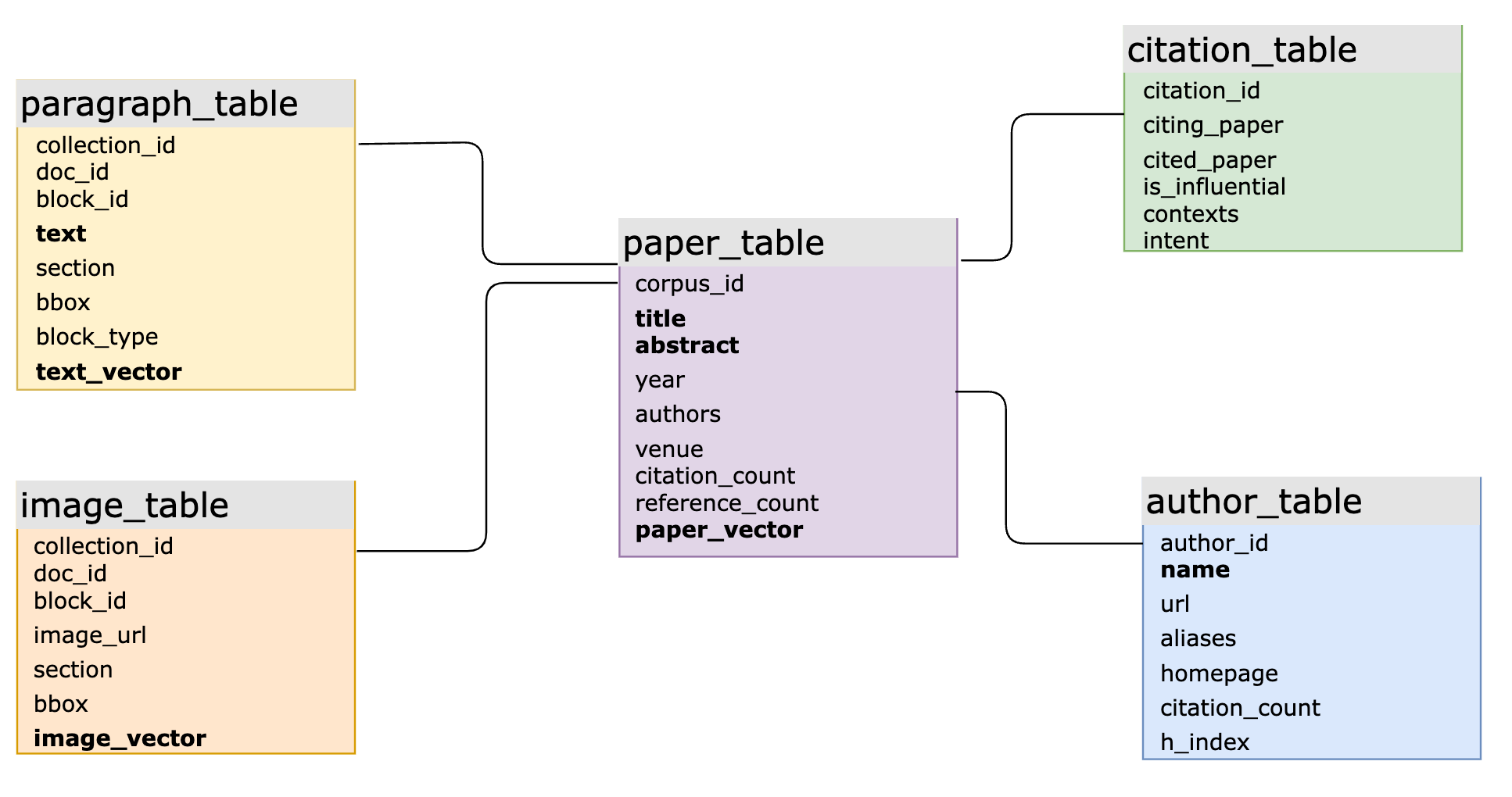
The main SQL vector database schema of a large-scale academic product supported by MyScale (columns in bold have associated vector indexes or inverted indexes)
# Improving RAG Accuracy and Cost-Efficiency
In real-world RAG systems, overcoming retrieval accuracy (and the associated performance bottlenecks) requires an efficient way to combine querying of structured, vector and keyword data.
For instance, in a financial application, when users query a document database asking, "What was the revenue of <company_name> in 2023 globally?" structured metadata like "<company_name>" and "2023" may not be captured by semantic vectors or present in consecutive text. Vector retrieval across the entire database can yield noisy results, reducing final accuracy.
However, information such as company names and years can often be obtained as document metadata. Using WHERE year=2023 AND company LIKE "%<company_name>%" as filtering conditions for vector queries can precisely pinpoint relevant information, significantly increasing system reliability. In finance, manufacturing and research, SQL vector data modeling and joint querying have been observed to improve precision from 60% to 90%.
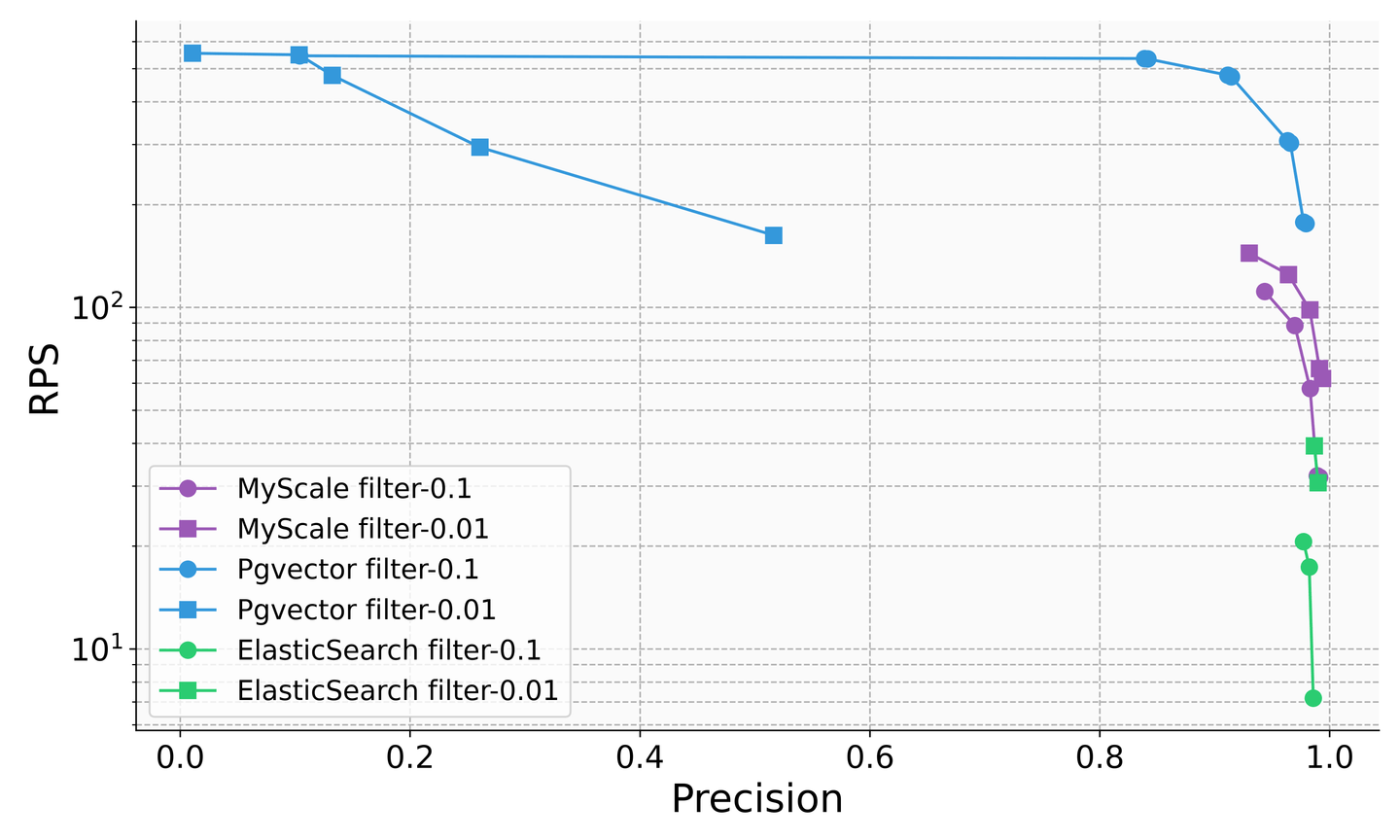
While traditional database products have recognized the importance of vector queries in the LLM era and started adding vector capabilities, there are still significant issues with the accuracy of their combined queries. For example, in filter-search scenarios, Elasticsearch's queries per second (QPS) rate drops to about five when the filtering ratio is 0.1, and PostgreSQL with the pgvector plugin has an accuracy of only about 50% when the filtering ratio is 0.01. This demonstrates unstable query accuracy and performance that greatly limit their usage. In contrast, SQL vector database MyScale achieves over 100 QPS and 98% accuracy in various filtering ratio scenarios, at 36% of the cost of pgvector and 12% of the cost of Elasticsearch.

# LLM + Big Data: Building a Next-Generation Agent Platform
Machine learning and big data have fueled the success of web and mobile apps. But with the rise of LLMs, we're shifting gears to build a new breed of LLM + big data solutions. Powered by MyScaleDB, our high-performance SQL vector database, these solutions unlock key capabilities for large-scale data processing, knowledge retrieval, observability, data analysis, few-shot learning, and more. Based on MyScaleDB, a closed-loop between data and AI is created, forming the foundation for our next-gen LLM + big data agent platform. This paradigm shift is already underway in sectors like scientific research, finance, industry, and healthcare.
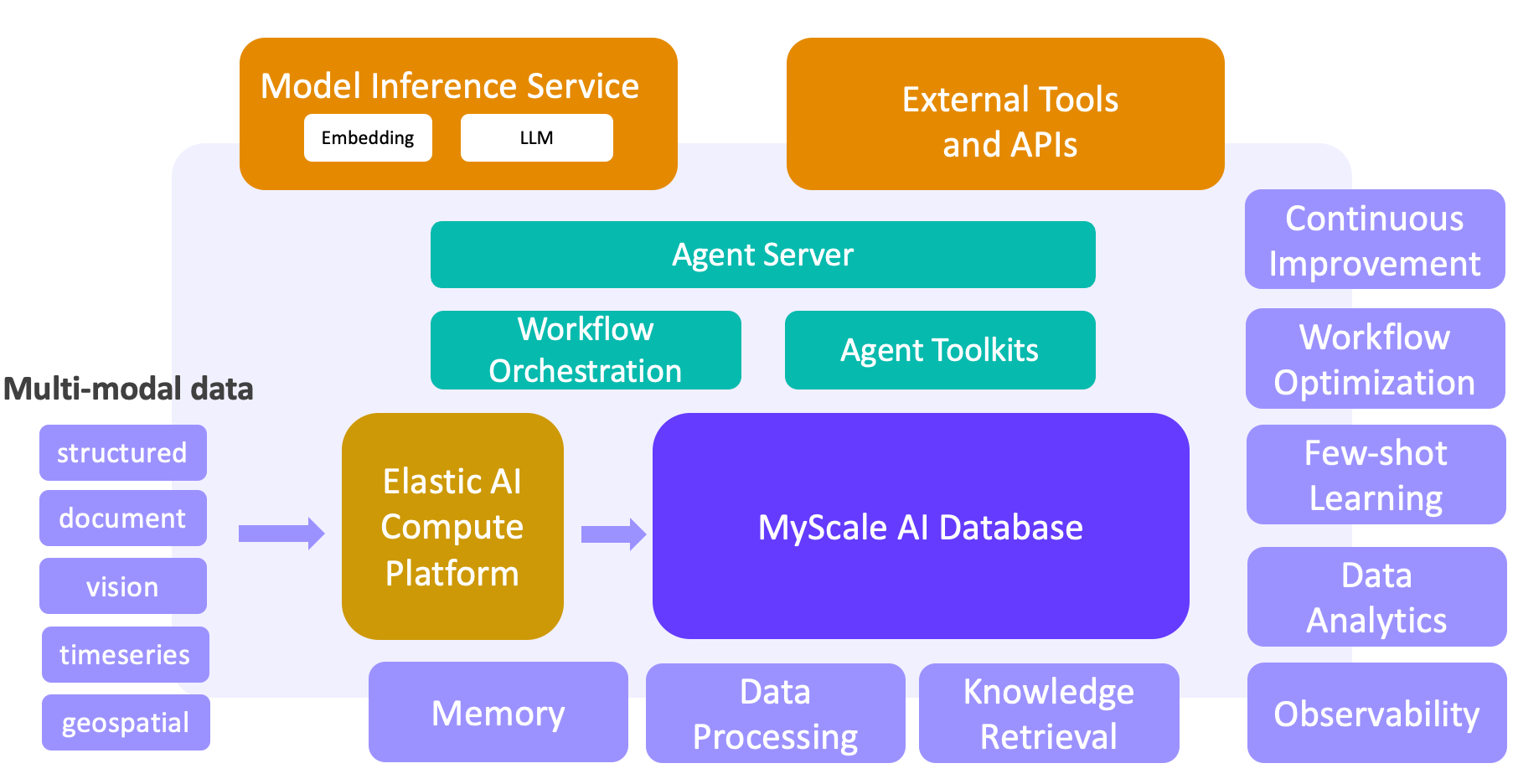
With the rapid development of technology, some form of artificial general intelligence (AGI), is expected to emerge within the next five to 10 years. Regarding this issue, we must ask: Do we need a static, virtual model, or another more comprehensive solution? Data is undoubtedly the important link connecting LLMs, users and the world. Our vision is to organically integrate LLMs and big data to create a more professional, real-time and collaborative AI system, which is also full of human warmth and value.
You are welcome to explore the open-source MyScaleDB repository on GitHub (opens new window), and leverage SQL and vectors to build innovative, production-level AI applications.



