
MyScale recently introduced the EmbedText (opens new window) function, a powerful feature that integrates SQL queries with text vectorization capabilities, converting text into numerical vectors. These vectors effectively map semantic similarities perceived by humans into proximities within a vector space. Using SQL's familiar syntax, EmbedText simplifies the vectorization process, improving its accessibility and allowing users to efficiently perform text vectorization in MyScale with providers such as OpenAI (opens new window), Jina AI (opens new window), Amazon Bedrock (opens new window), and others, both in real-time and batch-processing scenarios. Moreover, by leveraging automatic batching, the performance of processing large amounts of data is vastly improved. This integration eliminates the need for external tools—or complex programming—streamlining the vectorization process within the MyScale database environment.
# Introduction
The EmbedText function, defined as EmbedText(text, provider, base_url, api_key, others), is highly configurable and designed for both real-time search as well batch processing.
Note:
The detailed parameters of this function are available in our documentation (opens new window).
As described in the following table, the EmbedText function supports the following eight providers, each with unique advantages:
| Provider | Supported | Provider | Supported |
|---|---|---|---|
| OpenAI | ✔ | Amazon Bedrock | ✔ |
| HuggingFace | ✔ | Amazon SageMaker | ✔ |
| Cohere | ✔ | Jina AI | ✔ |
| Voyage AI | ✔ | Gemini | ✔ |
For instance, OpenAI's text-embedding-ada-002 model (opens new window) is well known for its robust performance. It can be utilized in MyScale with the following SQL command:
SELECT EmbedText('YOUR_TEXT', 'OpenAI', '', 'API_KEY', '{"model":"text-embedding-ada-002"}')
Jina AI's jina-embeddings-v2-base-en model (opens new window) supports extensive sequence lengths—up to 8k—offering a cost-effective and compact embedding dimension alternative. Here's how to use this model:
SELECT EmbedText('YOUR_TEXT', 'Jina', '', 'API_KEY', '{"model":"jina-embeddings-v2-base-en"}')
Note:
This model is currently only limited to English texts.
Amazon Bedrock Titan (opens new window), compatible with OpenAI models, excels in AWS integration and security features, providing a comprehensive solution for AWS users as the following code snippet describes:
SELECT EmbedText('YOUR_TEXT', 'Bedrock', '', 'SECRET_ACCESS_KEY', '{"model":"amazon.titan-embed-text-v1", "region_name":"us-east-1", "access_key_id":"ACCESS_KEY_ID"}')
# Creating Dedicated Functions
For ease of use, you can create dedicated functions for each provider. For instance, you can define the following function with OpenAI's text-embedding-ada-002 model:
CREATE FUNCTION OpenAIEmbedText ON CLUSTER '{cluster}'
AS (x) -> EmbedText(x, 'OpenAI', '', 'API_KEY', '{"model":"text-embedding-ada-002"}')
Next, the OpenAIEmbedText function is simplified into:
SELECT OpenAIEmbedText('YOUR_TEXT')
This approach simplifies the embedding process and reduces the repetitive entry of common parameters like API keys.
# Vector Processing with EmbedText
EmbedText revolutionizes vector processing in MyScale, particularly for vector search and data transformation. This function is pivotal in transforming both search queries and database columns into numerical vectors, a critical step in vector search and data management.
# Enhancing Vector Search
In vector similarity search, as detailed in our vector search guide (opens new window)—and described in the following code snippet—the traditional approach requires users to input query vectors in SQL manually.
SELECT id, distance(vector, [0.123, 0.234, ...]) AS dist
FROM test_embedding ORDER BY dist LIMIT 10
As set out in the following code snippet, using EmbedText streamlines the vector search process, making it more intuitive, simplifying the user experience considerably, and focusing a spotlight on query formulation rather than the mechanics of vector creation.
SELECT id, distance(vector, OpenAIEmbedText('the text query')) AS dist
FROM test_embedding ORDER BY dist LIMIT 10
# Streamlining Batch Transformations
Based on this diagram, we can see that the typical workflow for batch transformations involves pre-processing and storing the text data in a structured format.
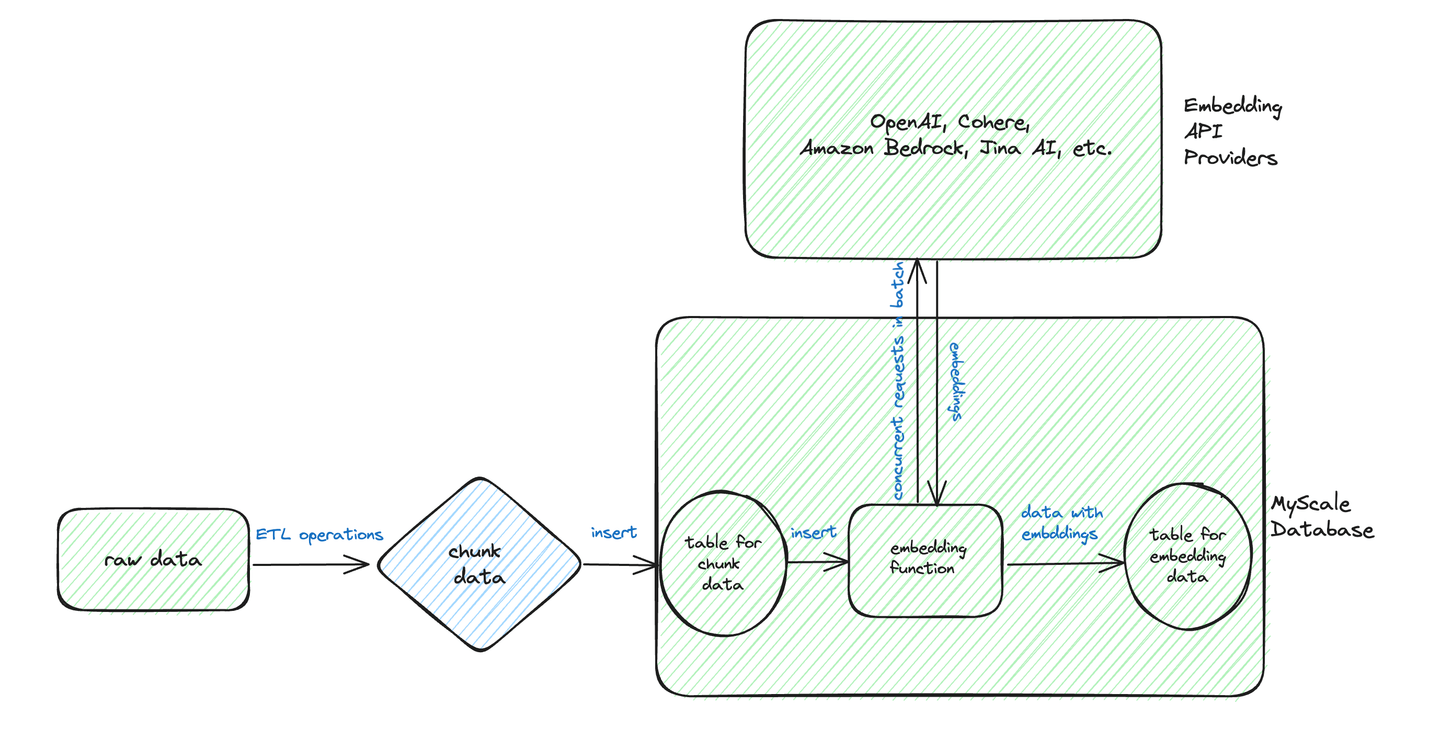
Let's assume we have the following chunk_data table containing raw data.
CREATE TABLE chunk_data
(
id UInt32,
chunk String,
) ENGINE = MergeTree ORDER BY id
INSERT INTO chunk_data VALUES (1, 'chunk1'), (2, 'chunk2'), ...
We can create a second table—the test_embedding table—to store vector embeddings created in the following way—using the EmbedText function.
CREATE TABLE test_embedding
(
id UInt32,
paragraph String,
vector Array(Float32) DEFAULT OpenAIEmbedText(paragraph),
CONSTRAINT check_length CHECK length(vector) = 1536,
) ENGINE = MergeTree ORDER BY id
Inserting data into test_embedding becomes straightforward.
INSERT INTO test_embedding (id, paragraph) SELECT id, chunk FROM chunk_data
Alternatively, EmbedText can be applied explicitly during insertion.
INSERT INTO test_embedding (id, paragraph, vector) SELECT id, chunk, OpenAIEmbedText(chunk) FROM chunk_data
As highlighted above, EmbedText includes an automatic batching feature that significantly improves handling efficiency when processing multiple texts. This feature manages the batching process internally before dispatching data to the embedding API, ensuring an efficient, streamlined data processing workflow. An example of this efficiency is demonstrated with the BAAI/bge-small-en model (opens new window) on an NVIDIA A10G GPU, achieving up to 1200 requests per second.

# Conclusion
MyScale's EmbedText function is a practical and efficient text vectorization tool, simplifing complex processes and democratizing advanced vector search and data transformation. Our vision is to seamlessly integrate this innovation into everyday database operations, empowering a broad range of users in AI/LLM-related data processing.



