
The exponential growth of the body of scientific literature has become a daunting obstacle for researchers, impeding their ability to uncover knowledge efficiently. According to the U.S. National Science Foundation, researchers spend 51% of their research time finding and digesting research materials.
Science Navigator (opens new window), developed by the AI for Science Institute in Beijing (AISI), addresses this challenge by providing an AI-powered platform for streamlined and precise literature reviews. This article explores the specific requirements of Science Navigator, the rationale behind selecting MyScale (opens new window) as its foundational database, and the tangible benefits it brings to the platform.
# Science Navigator: A Paradigm Shift in Scientific Literature Review
In scientific research, the literature review is a crucial step. While browsing and search-based retrieval remain mainstream methods, the rapid development of large language models (LLMs) has led more researchers to use AI methods for literature review. As an innovative project within the AI for Science infrastructure, Science Navigator 1.0 serves as an alternative to literature databases and knowledge bases. Science Navigator not only significantly improves the efficiency of researchers but also paves a new path for scientific exploration.

Based on the practical needs of scientific research, we found that many demands remain unmet. For instance, cross-disciplinary research has become the norm, making the requirement for cross-content retrieval more urgent. Unlike previous keyword-based retrieval methods, our requirements for content cross-retrieval are higher.
Today's LLMs can effectively improve the cross-cutting nature of retrieval, but they also have issues such as hallucinations and irrelevant answers. Given the rigor of scientific research, our demand for content traceability is growing stronger. Therefore, Science Navigator requires a powerful database that can effectively manage over 100 million research papers, efficiently store and index various types of data, and ensure the accuracy of queries. After evaluating different solutions, the advantages of MyScale became evident. Let's dive into these advantages.
# Requirements for Vector Databases
Science Navigator is a Retrieval-Augmented Generation (RAG) (opens new window) powered knowledge base Q&A system for researchers, covering over 200 million research papers and providing efficient professional knowledge acquisition services across multiple fields, including academia, materials science, chemical engineering, and biomedical sciences, significantly improving research efficiency.
To achieve this goal, we have the following requirements for the vector database:
# Data Management
Science Navigator includes a wide range of scientific literature, featuring complex and diverse data types. In addition to text, scientific literature also includes unique scientific representations, such as molecular formulas, mathematical equations, and charts, that encapsulate rich human wisdom. Effectively storing these various types and formats of data while ensuring their traceability is a challenge for the vector database.
# Data Query Accuracy
When serving researchers in enterprises and research institutions, Science Navigator must ensure the accuracy of query results to uphold the rigor of scientific research. Simultaneously, the system needs to maintain high-performance retrieval under high concurrency to enable researchers to access information anytime, anywhere, thereby improving research efficiency. This places high demands on the query accuracy and performance of the system.
# Multi-tenant Data Isolation
Finally, Science Navigator is designed to support user groups from multiple industries and fields. It must ensure that each user's data and services are independent (or encapsulated) and do not interfere with each other, to better meet the personalized needs of researchers from different academic backgrounds. This requires the underlying database to have flexible multi-tenant management capabilities.
# Why Choose MyScale
The goal of Science Navigator is to help researchers quickly obtain accurate research literature, making natural language query an essential function. To support natural language queries, we rely on technologies like Text2SQL (opens new window) and SelfQuery. MyScale, built on ClickHouse, supports the complete SQL syntax and provides the SelfQueryRetriever (opens new window) based on LangChain, which combines structured and unstructured queries, perfectly meeting our requirements.
Additionally, MyScale can handle structured data like a traditional relational database, allowing developers to perform complex SQL queries, aggregations, and analyses. Users can also use natural language questions, improving the system’s usability, especially for those unfamiliar with SQL, and lowering the usage threshold.
To ensure query accuracy and relevance, joint searches of vector and structured data are essential in addition to standalone vector searches. MyScale's architecture can store both structured and unstructured data, and seamlessly integrate vector search with structured data queries. Its combined search function can handle unstructured data and related metadata, enhance the understanding of query semantics, and provide richer search capabilities, thereby improving the relevance of searches.
Furthermore, MyScale's multi-tenant management function (opens new window) supports various strategies, such as table-based multi-tenancy and metadata-based management strategies, to meet our flexible requirements.
In summary, after researching the specialized vector databases and traditional databases with added vector plugins, only MyScale meets all requirements for Science Navigator, so it was chosen as its underlying database.
# The Solution
Science Navigator is an innovative academic paper search and conversational agent platform. One of its core advantages is the full utilization of the powerful functions of the MyScale AI database. MyScale not only supports efficient vector search and BM25 keyword search, but also provides comprehensive SQL support, a feature that brings great flexibility and efficiency to Science Navigator's data management.
# Data Storage
The platform's data foundation includes metadata for 200 million papers and full-text content for 3 million ArXiv papers. Through a specially developed PDF parsing tool, Science Navigator can accurately extract text, images, tables, and mathematical formulas from the papers. These structured and unstructured data are all stored in MyScale, retaining the original format while converting to vector form to support efficient searching.
# Data Management and Retrieval
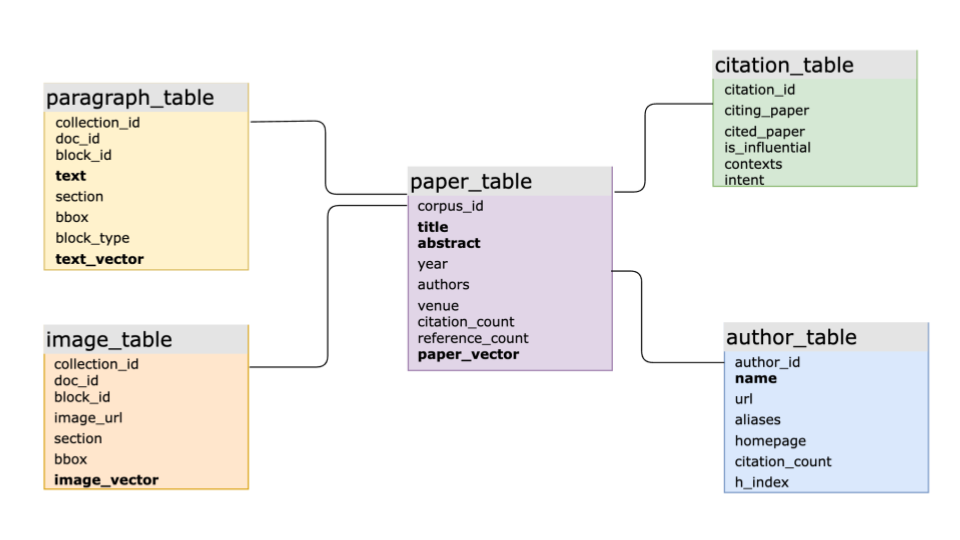
With the robust SQL support provided by MyScale, Science Navigator can store various complex paper metadata within a single database system. This includes the citation relationships between papers, detailed information about academic journals, and associations between authors and papers. This centralized data storage approach greatly simplifies the data management process while improving query efficiency.
As shown in the figure above, Science Navigator stores relevant paper data in multiple relational tables in MyScale:
- The paper_table stores the paper metadata;
- The text_table stores the full-text data parsed from the PDF;
- Keyword inverted indexes and vector indexes are created for the text and its vector representations;
- For the images parsed from the PDFs: their embeddings are stored in the image_table, and vector indexes are created;
- For author metadata in the author_table, only keyword inverted indexes for author names are created; and
- Citation relationships between papers are stored directly in the citation_table relational table.
Science Navigator's search function fully utilizes MyScale's hybrid search capabilities (opens new window). Users can use both vector search and keyword search, combined with SQL queries, to precisely locate the academic resources they need. For example, they can easily implement complex queries based on factors like paper content similarity, publication year, and citation count.
For the conversational function, MyScale's SQL support allows Science Navigator to quickly retrieve and combine various relevant information, providing users with comprehensive and accurate answers. The system can easily relate paper content, author information, citation networks, and other data to generate in-depth academic insights.
# System Optimization and Maintenance
To continuously optimize performance, Science Navigator utilizes MyScale to store and analyze user interaction data. Chat histories, large model invocation traces, and other information are all recorded in MyScale. By querying and analyzing this data using SQL, the platform can gain insights into user behavior patterns and optimize the search algorithms and dialogue models.
The robust SQL support provided by MyScale also equips Science Navigator with powerful data management and analysis capabilities. Platform administrators can use familiar SQL syntax to perform complex data operations and analyses, such as tracking popular research topics, analyzing author collaboration networks, and evaluating journal impact factors.
In summary, the comprehensive SQL support of MyScale, combined with its strengths in vector search and keyword search, has made Science Navigator a powerful, flexible, and efficient academic research assistant. It not only provides advanced search and dialogue capabilities but also offers strong support for the data management and analysis of the entire academic ecosystem.
# Key Benefits MyScale Brings to Science Navigator
By integrating MyScale, Science Navigator leverages several advanced capabilities that significantly enhance its performance and usability. These key benefits include:
- Large-scale Multimodal Data Storage
Science Navigator is the first paper retrieval system capable of performing semantic search on the metadata of 200 million papers and the full-text content of 3 million ArXiv papers using embedded vectors.
- Achieving Precise Large-scale Data Retrieval
Science Navigator's powerful natural language conversational retrieval capabilities can quickly locate the exact information researchers need, making literature retrieval simpler and faster than ever before. This is due to the integration of the MyScale AI database into the platform, which, when combined with the advantages of large language models, achieves an effect equivalent to models with 3-6 times the parameters, significantly reducing training and inference costs.
MyScale provides an effective memory carrier for large models, meeting the requirements for dynamic and rapid updates of the research literature knowledge base, as well as the need for accurate output results. This enables low-cost and high-efficiency information storage without occupying model space. With the help of MyScale, Science Navigator achieves millisecond-level retrieval of billion-scale vectors and massive structured data, reducing researchers' average literature search time by over 90% while maintaining over 95% question-answering accuracy for complex domain-specific problems.
- Cost Efficiency
While ensuring high accuracy and high efficiency, the MyScale AI database employs a unique MSTG vector indexing algorithm, storing the original vectors on NVMe SSDs. Compared to the pure memory-based HNSW vector indexing algorithm, the memory consumption is reduced by 16 times, and the total cost is reduced by more than 90%.

# Conclusion
Science Navigator is more than just an AI platform tailored for researchers; it is a comprehensive research ecosystem. It offers a wide range of tools, from knowledge extraction and frontier progress tracking to idea generation and literature review writing. By opening API interfaces for most of its capabilities, Science Navigator enables users to build their own applications and intelligent agents on the platform, addressing the complex and personalized needs of scientific research.
Looking ahead, with the continued support of MyScale, Science Navigator will expand to include high-quality research literature from additional industries, continually optimize system performance, and solidify its position as a powerful and user-friendly research literature navigator for researchers.




