
![]()
LlamaIndex (opens new window) is a data framework designed for implementing applications using Large Language Models (LLMs), simplifying parsing, storing, and retrieving various types of document data, and adding immense value to the capabilities of LLM applications. This mechanism is commonly referred to as Retrieval-Augmented Generation (RAG).
To help you understand how to use LlamaIndex to implement this mechanism, this article will build a simple document query engine to demonstrate the process.
# MyScale
While LlamaIndex can handle various types of source data, it doesn't store or index this data. We still need a storage system. MyScale (opens new window) is a vector database that supports SQL and is easy to use, with its free version supporting up to 5 million vector data points. Most importantly, LlamaIndex supports MyScale vector databases (opens new window). You can connect to a MyScale database for storing and querying data using MyScaleVectorStore and MyScaleReader and perform the following data operations through LlamaIndex:
| Vector Store | Type | Metadata Filtering | Hybrid Search | Delete | Store Documents |
|---|---|---|---|---|---|
| MyScale | cloud | ✓ | ✓ | ✓ | ✓ |
This suite of operations provides comprehensive functionalities. Now, let’s start building our LLM application using these operations.
# Preparation
Note:
All related code mentioned in this article can be found on GitHub in the repository myscale/llama_index_myscale (opens new window).
# Data
We used the MyScale official documentation (MyScale Docs (opens new window)) in Markdown format as our raw data. You can also view and download these files on GitHub (opens new window).
# Dependencies
- Python 3.8.18
- LlamaIndex 0.9.5
- MyScale
# Process Flow
Building a Retrieval-Augmented Generation (RAG) application involves multiple processing steps, as the following diagram highlights. Firstly, we must process the raw data offline, including splitting the text data—stored in flat files—into data nodes based on specific criteria—or rules. Once this is complete, we need to calculate each data node's vector representation. And lastly, we must store the data in the database.
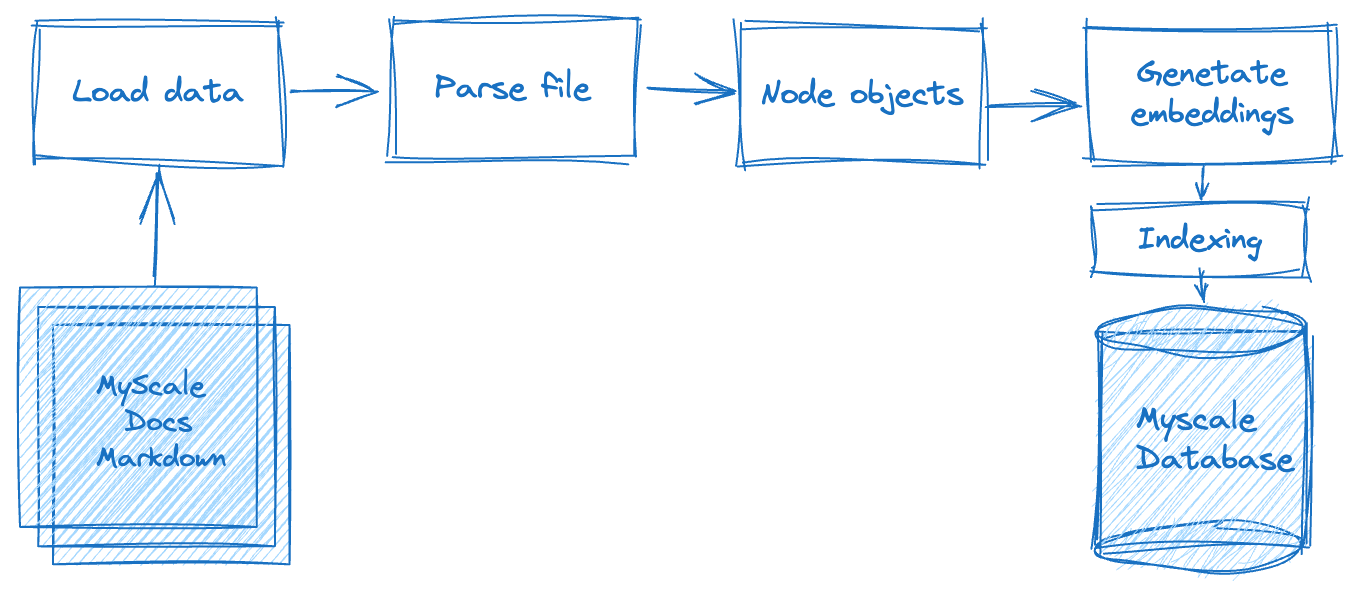
In the second phase—the data retrieval phase—we query and merge the relevant document data based on this query. This data is then requested by, and returned to, the LLM system, returning the expected results.
Let's now explore how to integrate LlamaIndex with MyScale to accomplish these steps.
# Loading the Data
In this phase, we need to read the downloaded document files, convert them into MyScale document objects, and utilize LlamaIndex's rich document processing capabilities, including handling Markdown, PDFs, Word documents, PowerPoint decks, images, audio, and video. For .md documents, the MarkdownReader is used, as demonstrated below:
# utils.py
from llama_index import download_loader
from llama_index import Document
from typing import Dict, List, Union
from pathlib import Path
UnstructuredReader = download_loader("MarkdownReader")
loader = UnstructuredReader()
def load_and_parse_files(file_row: Dict[str, Path]) -> List[Dict[str, Document]]:
documents = []
file = file_row["path"]
if file.is_dir():
return []
# Skip all non-md files like png, jpg, etc., html.
if file.suffix.lower() == ".md":
loaded_doc = loader.load_data(file=file)
loaded_doc[0].extra_info = {"path": str(file)}
documents.extend(loaded_doc)
return [{"doc": doc} for doc in documents]
# Parsing the Documents
After reading the text segments from these documents, we need to encapsulate them into data nodes for the next vectorization operation. To ensure format consistency, we continue to use the MarkdownNodeParser. The processing flow for this part is as follows:
# utils.py
from llama_index.node_parser import MarkdownNodeParser
from llama_index.data_structs import Node
def convert_documents_into_nodes(documents: Dict[str, Document]) -> List[Dict[str, Node]]:
parser = MarkdownNodeParser()
document = documents["doc"]
nodes = parser.get_nodes_from_documents([document])
return [{"node": node} for node in nodes]
# Vectorization
Vectorization is a crucial and time-consuming step. This involves vectorizing the text content of the data nodes returned in the previous step and storing the vectors in the "embedding" field of the data nodes. We use the sentence-transformers/all-mpnet-base-v2 model (opens new window), which can be obtained from Hugging Face. LlamaIndex will automatically assist us with downloading and applying these embeddings in our application.
# utils.py
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
class EmbedNodes:
def __init__(self):
self.embedding_model = HuggingFaceEmbeddings(
# Use all-mpnet-base-v2 Sentence_transformer.
# This is the default embedding model for LlamaIndex/Langchain.
model_name="sentence-transformers/all-mpnet-base-v2",
model_kwargs={},
# Use GPU for embedding and specify a large enough batch size to maximize GPU utilization.
# Remove the "device": "cuda" to use CPU instead.
encode_kwargs={"batch_size": 100}
)
def __call__(self, node_batch: Dict[str, List[Node]]) -> Dict[str, List[Node]]:
nodes = node_batch["node"]
text = [node.text for node in nodes]
embeddings = self.embedding_model.embed_documents(text)
assert len(nodes) == len(embeddings)
for node, embedding in zip(nodes, embeddings):
node.embedding = embedding
return {"embedded_nodes": nodes}
# Executing Locally and Storing in MyScale
We introduced the primary operations of parsing and vectorizing Markdown documents in the above processes. Next, we need to output the data and build an index. In LlamaIndex, we can use MyScaleVectorStore to perform these non-complex operations, as seen in the following Python script:
Note:
This script contains the entire data processing flow.
# create_vector_index.py
import clickhouse_connect
import utils
from pathlib import Path
from llama_index import VectorStoreIndex
from llama_index.vector_stores import MyScaleVectorStore
from llama_index.storage import StorageContext
all_docs_gen = Path("./docs.myscale.com/").rglob("*")
all_docs = [{"path": doc.resolve()} for doc in all_docs_gen]
blog_nodes = {"embedded_nodes": []}
for docs in all_docs:
loaded_docs = utils.load_and_parse_files(docs)
for doc in loaded_docs:
nodes = utils.convert_documents_into_nodes(doc)
newNodes = {"node": []}
for node in nodes:
newNodes["node"].append(node["node"])
embedNodes = utils.EmbedNodes()
tmpNodes = embedNodes(newNodes)
blog_nodes["embedded_nodes"].extend(tmpNodes["embedded_nodes"])
client = clickhouse_connect.get_client(
host='{MYSCALE_CLUSTER_URL}',
port=443,
username='{YOUR_USERNAME}',
password='{YOUR_PASSWORD}'
)
vector_store = MyScaleVectorStore(myscale_client=client)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
VectorStoreIndex(blog_nodes["embedded_nodes"], storage_context=storage_context)
For reusability, the functions load_and_parse_files, convert_documents_into_nodes, and EmbedNodes are placed in utils.py.
# Building the Query Service
Once the data is stored in MyScale, we can use MyScaleVectorStore and the LLM's API to handle user queries, per the following script—query_myscale.py. The following is the content of , which includes the following main steps:
This script includes these main steps:
- Read the user's input query from the terminal and vectorize the query.
- Use
llama_index.vector_stores.MyScaleVectorStoreto query data related to the query using Hybrid Search mode. This mode ensures a certain level of relevance in both text and vector distance. - Synthesize the response by sending the documents obtained in the previous step to the LLM to generate the final result.
# query_myscale.py
import clickhouse_connect
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from llama_index.schema import NodeWithScore
from llama_index.vector_stores import MyScaleVectorStore, VectorStoreQuery
from llama_index.vector_stores.types import VectorStoreQueryMode
# Add your OpenAI API Key here before running the script.
model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")
client = clickhouse_connect.get_client(
host='{MYSCALE_CLUSTER_URL}',
port=443,
username='{YOUR_USERNAME}',
password='{YOUR_PASSWORD}'
)
# input query
query = input("Query: ")
while len(query) == 0:
query = input("\nQuery: ")
# embedding query
embedded_query = model.embed_query(query)
# send query to myscale by using llama_index.vector_stores.MyScaleVectorStore
vector_store = MyScaleVectorStore(myscale_client=client)
vector_store_query = VectorStoreQuery(
query_embedding=embedded_query,
similarity_top_k=20,
mode=VectorStoreQueryMode.HYBRID
)
result = vector_store.query(vector_store_query)
scoreNodes = [NodeWithScore(node=result.nodes[i], score=result.similarities[i]) for i in range(len(result.nodes))]
# synthesize the response
from llama_index.response_synthesizers import (
get_response_synthesizer,
)
synthesizer = get_response_synthesizer()
response_obj = synthesizer.synthesize(query, scoreNodes)
print(f"Response: {str(response_obj.response)}")
Note:
Replace placeholders such as {MYSCALE_CLUSTER_URL}, {YOUR_USERNAME}, and {YOUR_PASSWORD} with your actual MyScale cluster information.

# Executing the Script
Execute the script, and after the prompt, input a query to receive the following response:
$ python query_myscale.py
Query: How to create a MyScale Cluster?
Response: To create a MyScale Cluster, you can follow these steps:
1. Go to the Clusters page.
2. Click on the "+ New Cluster" button.
3. Name your cluster.
4. Click "Launch" to run the cluster.
Once the cluster is created, it will start automatically. Please note that the cluster will be terminated if there is no activity for 7 days, and all data in the cluster will be deleted.
You can input various MyScale-related questions. This application is designed to provide valuable answers.
# Going Further
We have successfully built a fully functional LLM application with MyScale and LlamaIndex, demonstrating its effective performance. How do we speed up the embedding process to cope with one hundred thousand or even millions of document data?
Fortunately, we can use Ray, a framework designed for machine learning, in combination with LlamaIndex and MyScale for distributed computing to enhance data processing efficiency. You can refer to the Ray official documentation, Installing Ray (opens new window), or Ray on Kubernetes (opens new window), to build a local or Kubernetes-based cluster.
Assuming you already have a RayCluster Head on Local Host or have enabled Post Forward for RayCluster Head in the Kubernetes cluster, you can use the following code directly to improve the processing of embeddings with parallel computing, significantly accelerating data processing speeds and efficiencies:
# create_vector_index_by_ray.py
import clickhouse_connect
import utils
import ray
from pathlib import Path
from llama_index import VectorStoreIndex
from llama_index.vector_stores import MyScaleVectorStore
from llama_index.storage import StorageContext
from ray.data import ActorPoolStrategy
all_docs_gen = Path("./docs.myscale.com/").rglob("*")
all_docs = [{"path": doc.resolve()} for doc in all_docs_gen]
ds = ray.data.from_items(all_docs)
loaded_docs = ds.flat_map(utils.load_and_parse_files)
nodes = loaded_docs.flat_map(utils.convert_documents_into_nodes)
embedded_nodes = nodes.map_batches(
utils.EmbedNodes,
batch_size=100,
compute=ActorPoolStrategy(size=4),
num_gpus=0)
blogs_nodes = []
for row in embedded_nodes.iter_rows():
node = row["embedded_nodes"]
assert node.embedding is not None
blogs_nodes.append(node)
client = clickhouse_connect.get_client(
host='{MYSCALE_CLUSTER_URL}',
port=443,
username='{YOUR_USERNAME}',
password='{YOUR_PASSWORD}'
)
vector_store = MyScaleVectorStore(myscale_client=client)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
VectorStoreIndex(blogs_nodes, storage_context=storage_context)
These processes, using the same input and output described above in the Executing Locally and Storing in MyScale section, can also query the relevant vector data stored in the MyScale database. You can then execute queries using query_myscale.py.
# In Conclusion
MyScale and LlamaIndex are two excellent tools for LLM processing. They can help you quickly build your LLM application. When faced with challenging data scale issues, you can use Ray for distributed processing, combining it with LlamaIndex and MyScale to significantly improve the ease of development.
Finally, for large-scale RAG applications, visit myscale.com (opens new window) to set up your cluster without delay!



