
This blog was originally published on Usama's Blog (opens new window)
In the past, I have been using ClickHouse (opens new window) for different Data warehousing and Data analytics projects. But after the boom of Generative AI and vector embeddings, I was looking for a database to use with cutting-edge technologies. There were so many vector databases like Pinecone (opens new window), Weaviate (opens new window), and Milvus (opens new window), but all of these Vector DBs were only specialized for vectors and required a lot of time to thoroughly understand the fundamentals and get used to the syntax.
MyScale (opens new window) is not as popular as those vector databases I mentioned above and listed at the end of the Vector DB Feature Matrix (opens new window). I explored it further and I got to know that It had all the functionalities I needed with super easy documentation. It's built on top of ClickHouse and can store vectors for Generative AI applications and tabular data for normal SQL applications. My previous experience with ClickHouse and SQL helped me to get used to the fundamentals very quickly and I have been using it for the last 4 months.
# MyScale vs ClickHouse
I have tried to compare both in a very easy way so that you can get a clear idea about these two databases.
| Feature | ClickHouse | MyScale |
|---|---|---|
| Base Technology | Open-source column-oriented DBMS | Cloud-based SQL vector database built on ClickHouse |
| Primary Use | OLAP with real-time SQL query processing | AI applications, combining vector similarity search with SQL |
| Data Storage Method | Columnar storage for efficient querying | Columnar storage, handling vectors and structured data |
| Data Type Handling | Structured data | Both structured data and vectors |
| Query Language | SQL | Full SQL support, including natural language queries |
| Key Features | Real-time analytical reports, efficient in specific queries | AI integration, accuracy, performance, and cost-efficiency |
| Use Case | Traditional OLAP scenarios | Advanced AI and machine learning applications |
I hope you have understood the differences and why I chose to go with MyScale. Let's explore an interesting and helpful feature they added a few days back.
# Exploring MyScale Playground
When I moved from ClickHouse to MyScale, there were a few things I thought MyScale needed to work on, and one of those was a playground to write queries and see the results without sign-up. MyScale gradually made many improvements in its infrastructure, and they have incorporated most of my desired features, but a playground was still missing.
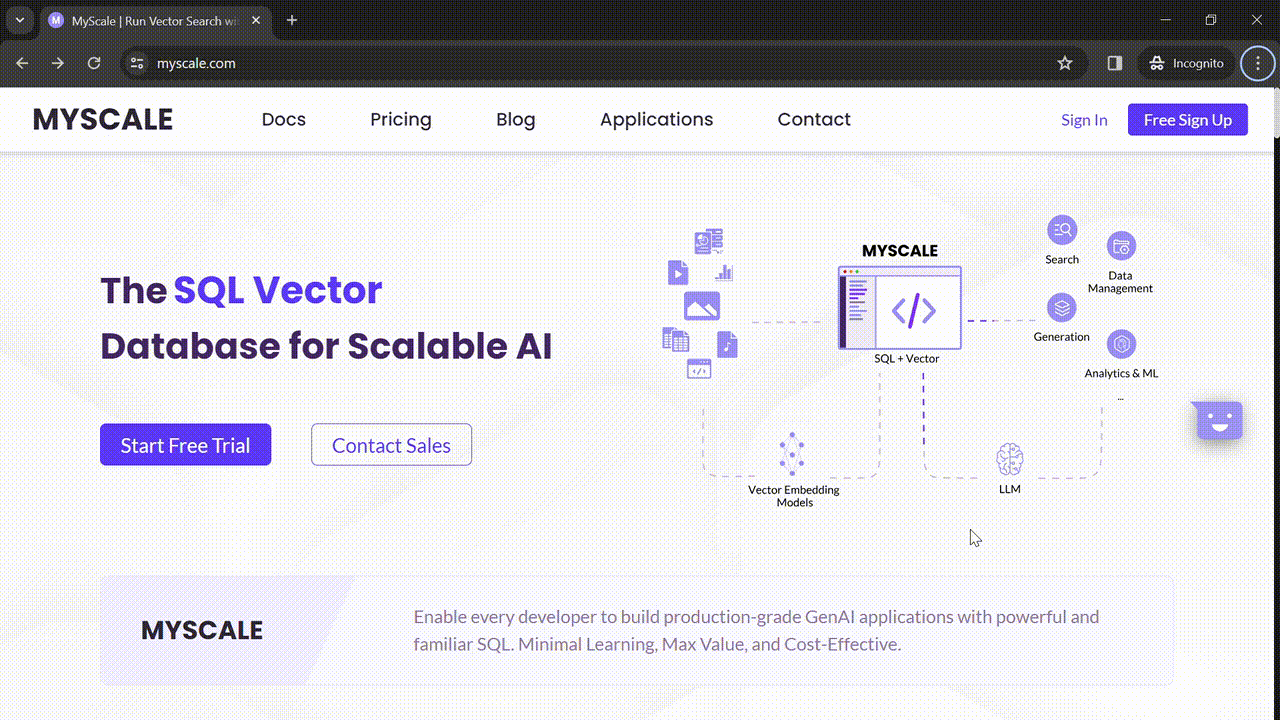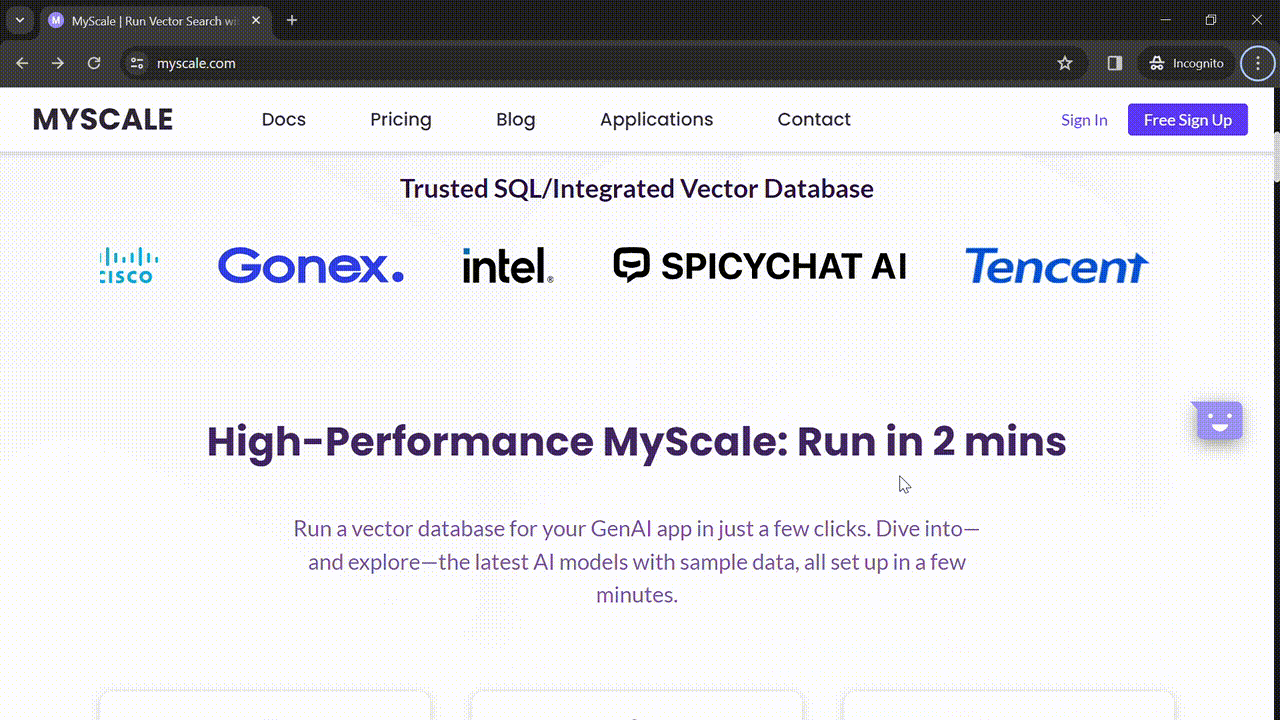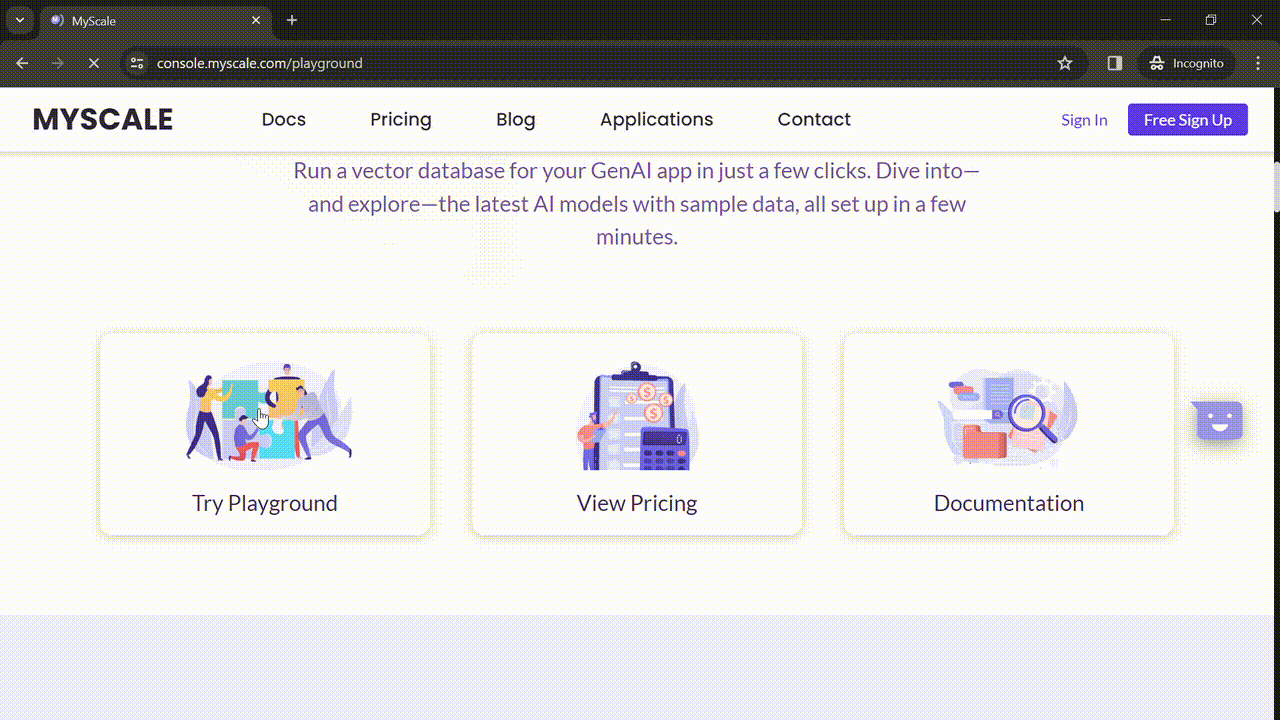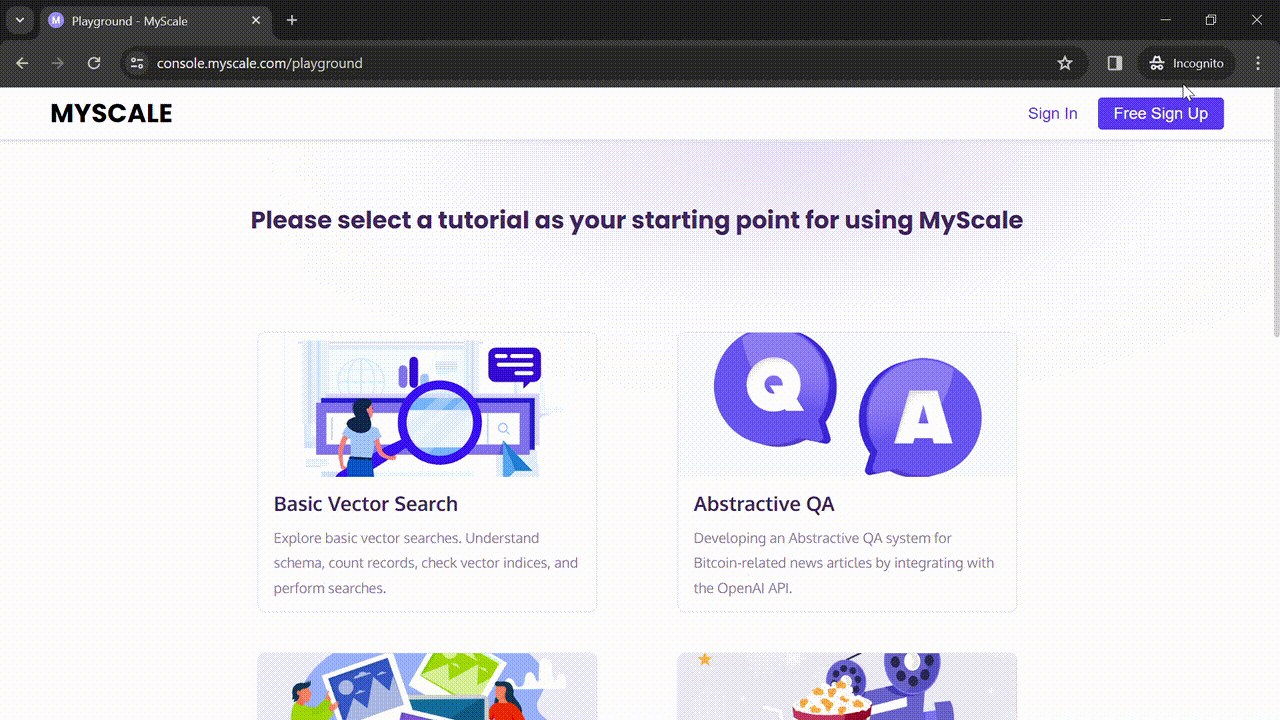
Recently, they have finally added a playground to their platform, and I'm simply loving it. I have explored playgrounds from many other providers before, but I think it's the only playground that allows the execution of SQL and vector joint queries (opens new window), which is a rare feature.
Let's explore the MyScale playground (opens new window) together now.
# User-friendly Interface
In the playground, you will see that several sample applications have already been built for different scenarios, and different datasets uploaded for each application.
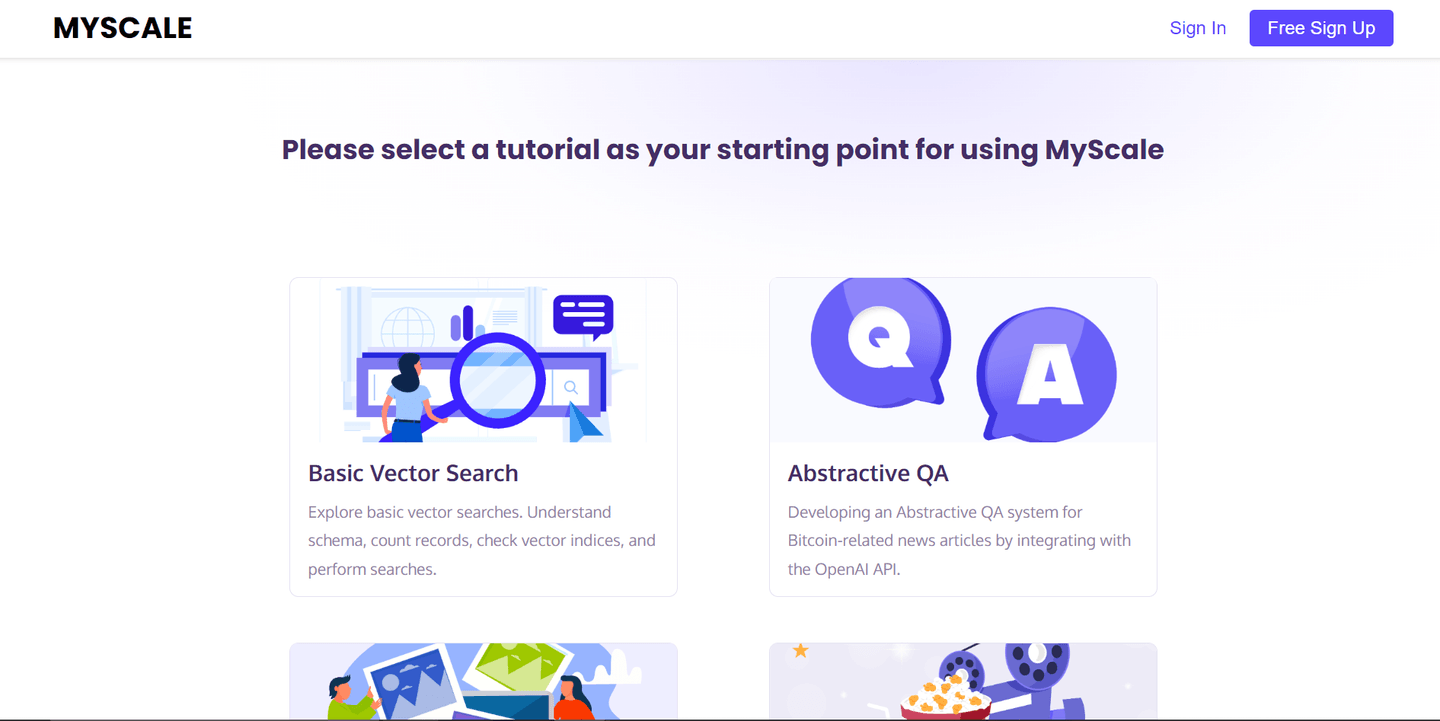
Of all these sample applications, I enjoy the Working with Texts (opens new window) application the best. It has the pre-loaded ArXiv dataset, which includes over 2.2 million papers with metadata information.
Open the application, you will see an interface like this:
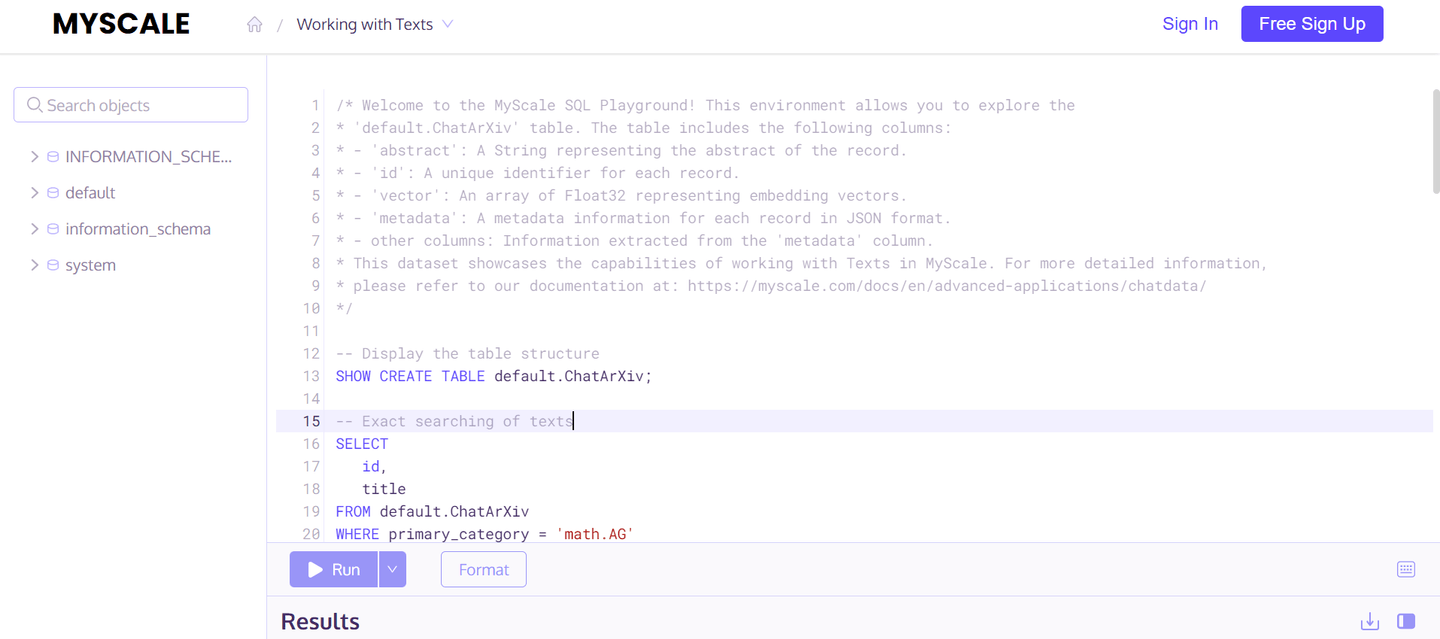
The first thing you may notice when you open any application is its descriptions and details of the table used for this application. By reading the description, you can easily understand what the application is used for and how to play around with the dataset. All the available databases are shown on the left side for you to explore the pre-existing tables.
Then, there are different sample commands added that you can use to explore the application and experiment. Let's look at some of the sample queries:
# Simple Query
Once you execute the first query, you will see the command used to create the table for this application.
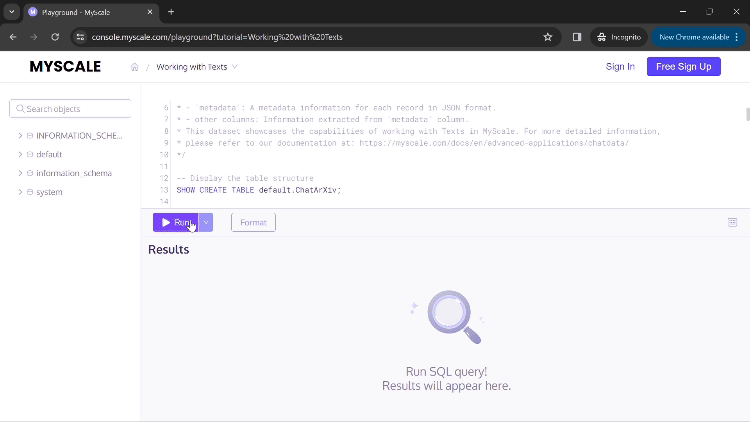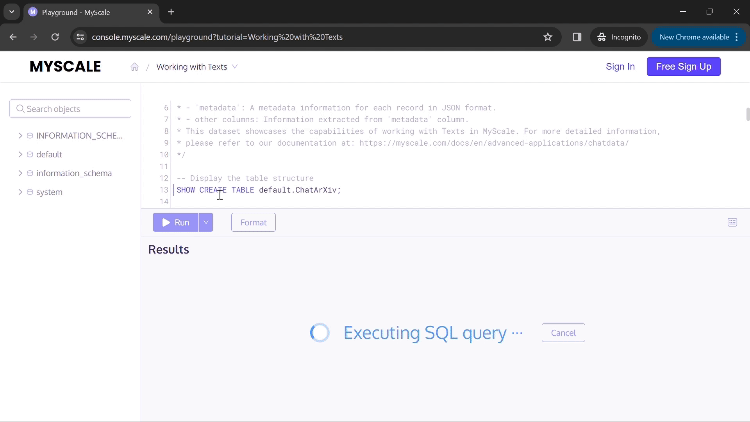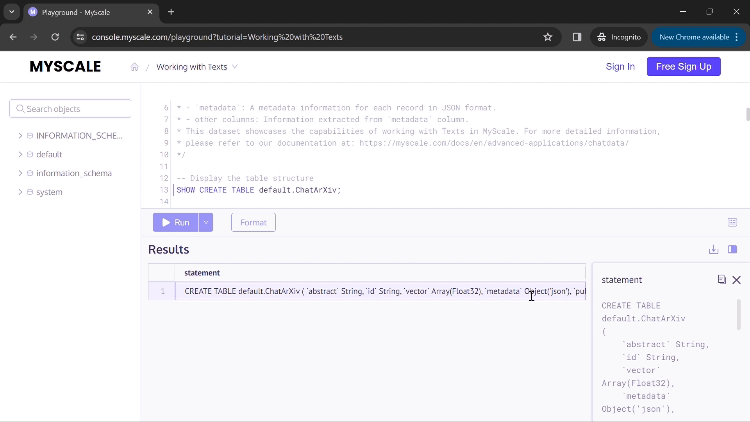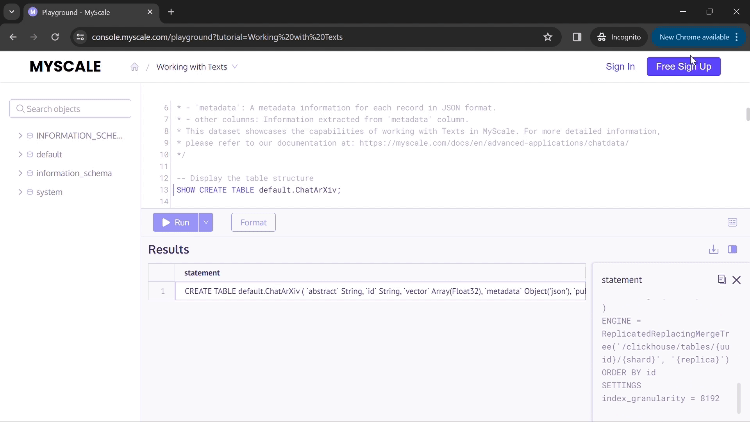
You can click 'Run' to execute your command and display the results. If a result contains values too large to be fully seen in the columns, you can click on that column, and a new dialogue box will open, displaying the complete results (shown in the above GIF).
It also added some sample queries with pre-built functions (opens new window). However, I will skip these queries and proceed directly to the last query to perform the Vector SQL query.

# Vector SQL Search Query
As I have already discussed that MyScale is a very dynamic database where you can execute SQL with advanced vector search queries. This combination allows MyScale to handle complex datasets in a more effective and cost effective way. A few sample queries are provided just for better understanding the dataset but the potential applications of MyScale are beyond these examples. For example, you can utilize the familiar SQL syntax for in-depth analysis of the dataset, thereby gaining valuable insights. Take the following query, it provides an insight into the evolution and current trends in quantum computing research:
WITH recent_quantum_papers AS (
SELECT id, vector, title, abstract, pubdate
FROM default.ChatArXiv
WHERE abstract LIKE '%quantum computing%' AND pubdate > '2019-01-01'
),
reference_vector AS (
SELECT vector
FROM recent_quantum_papers
ORDER BY pubdate DESC
LIMIT 1
)
SELECT
id,
title,
abstract,
EXTRACT(YEAR FROM pubdate) AS year,
distance(vector, (SELECT vector FROM reference_vector)) AS similarity
FROM recent_quantum_papers
ORDER BY year DESC, similarity ASC
LIMIT 10;
This query filters academic papers on quantum computing published after 2019, using a vector from the most recent paper to measure contextual similarity among them. This approach not only sorts papers chronologically but also by their relevance to the latest research trends. The following pitcure shows the search result that contains the meta data of the documents and similarity distance as well:
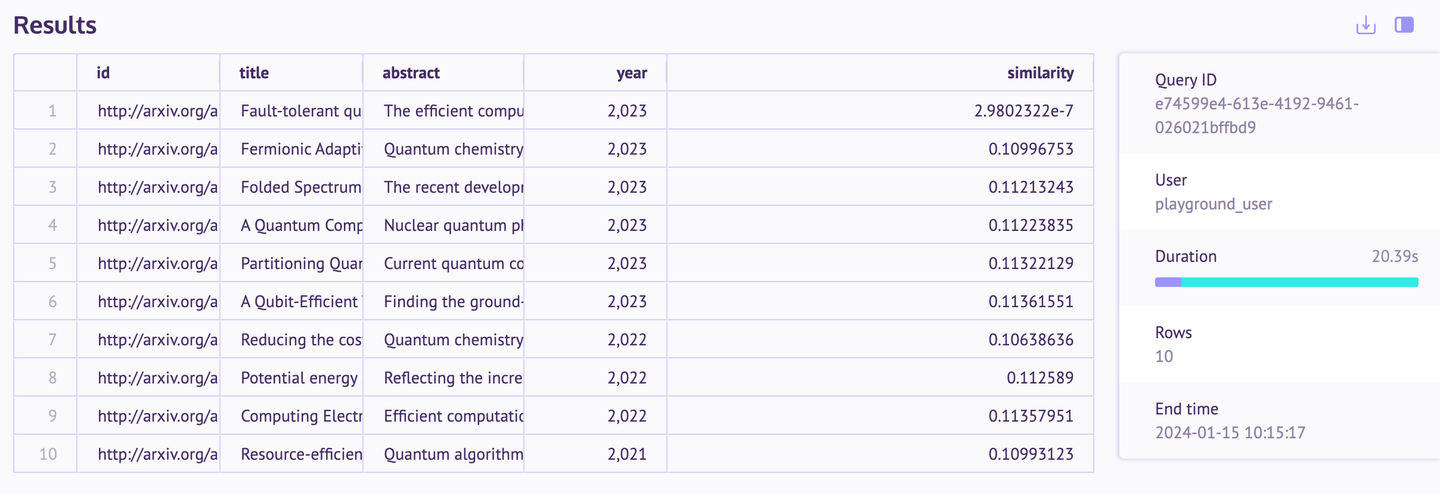
You can also write much more complex queries with MyScale as it has full SQL and vector support. The other sample apps are also quite impressive. If anyone is interested, they can explore them.
Note: Uploading data directly to MyScale Playground is not supported. To use your data, first login or signup on MyScale, then follow the step-by-step instructions provided in the quickstart guide (opens new window).
# Conclusion
In summary, I have a great experience with the MyScale playground, which provides a user-friendly environment for seamlessly integrating SQL and vector queries. The inclusion of industry-standard sample applications proved invaluable for learning and transitioning from traditional databases.
Built on the robust foundation of ClickHouse, MyScale encompasses all its functionalities while catering to the demands of modern AI applications. Its support for integration with OpenAI (opens new window), LangChain (opens new window), and LlamaIndex (opens new window) further underscores its versatility.
If you're interested in MyScale, it's worth exploring the MyScale playground, especially considering that the interface of the playground is so simple and easy to start with. That's all my exploration of the MyScale playground. Feel free to share your thoughts or engage in discussions in the comments.



