
# About Cowarobot

Founded in 2015, Cowarobot is a company that specializes in providing turnkey solutions for autonomous driving in complex urban environments. As of mid-2022, they had a presence in over 10 cities in China, and a fleet of over 1,000 autonomous vehicles. They have also collaborated with Chinese automakers such as Cherry, BAIC, Shaanxi Automobile, and Zoomlion to develop urban logistics delivery and transportation solutions in these cities.
# Prior to using MyScale
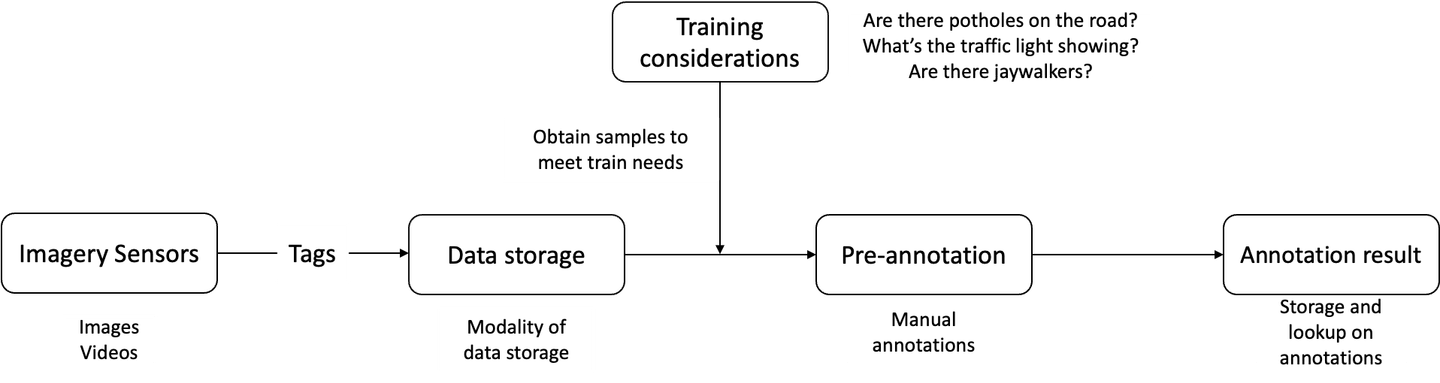
Cowarobot’s main workflow for training their autonomous driving fleet is divided into five sections:
- Storing raw data and labels in a centralized storage
Cowarobot specializes in collecting and processing raw video and spatial data that is crucial for autonomous vehicles, such as dynamic information like nearby vehicles, roadblocks, and traffic signals, in addition to traditional data like road surfaces, pavements, maps, and speed limits. The data is labeled and organized into folders with multiple levels, which are then saved to local drives. However, Cowarobot faces a significant challenge in terms of data storage due to the vast amount of data produced. The company faces the challenge of procuring and maintaining a large number of hard disk drives to store data in a centralized, sustainable manner. In addition, a minimum of one million data samples are required for accurate real-time object recognition, segmentation and label detection.
- Executing training tasks
Cowarobot uses the collected raw data to train its models, enabling its autonomous vehicles to navigate from point A to point B, maintain a safe speed relative to other cars, avoid obstacles, and obey traffic signals. To ensure the vehicles can handle changing road conditions, training data must be constantly updated. For example, if road markings are changed, previous data labels must be rewritten to reflect the changes. Similarly, if the vehicle encounters new or unexpected situations, such as jaywalking pedestrians or a police officer signaling it to stop, it must be trained to respond appropriately. These updates require Cowarobot to repeatedly acquire and label new data, as well as re-label existing data, incurring substantial training costs. These costs and frequent updates limit the types, frequency, and quality of training tasks that Cowarobot can complete.
- Obtaining new samples
Cowarobot lacks the means to easily access and retrieve the labels they have previously assigned to their data, and they are unable to recall previous labels. This limitation means that the company can only support model training tasks with their existing data. Cowarobot must manually export all data from their local drives in order to use it, which is a time-consuming process. Additionally, the existing data is insufficient to support the training of Cowarobot’s models, so the company must continue to collect new data and generate training samples. However, the current workflow requires Cowarobot to manually export all data from the local drives after each update is made, which is a tedious and time-consuming process.
- Data labels
The manual nature of Cowarobot's current label task process impedes the efficiency of generating datasets to update their models and deploy new updates to their autonomous fleet. This labor-intensive and time-consuming procedure hinders the company's ability to keep its models updated with the most recent data.
- Model training
Currently for model training, Cowarobot employs a distributed architecture for model training, in which multiple supercomputers are utilized to harness their computing power for various stages of the training process. This strategy is more economical than using a single, more powerful supercomputer. However, one disadvantage of this method is that the training samples must be transmitted between computers, either through the network or offline, which can be cumbersome and time-consuming.
In addition, the output of the trained models is underutilized. Completed training tasks would allow Cowarobot to use these models directly online, but the stored data outside of the model training samples has not been updated to reflect the new model.
# Adopting MyScale as the data warehousing solution for their autonomous vehicles
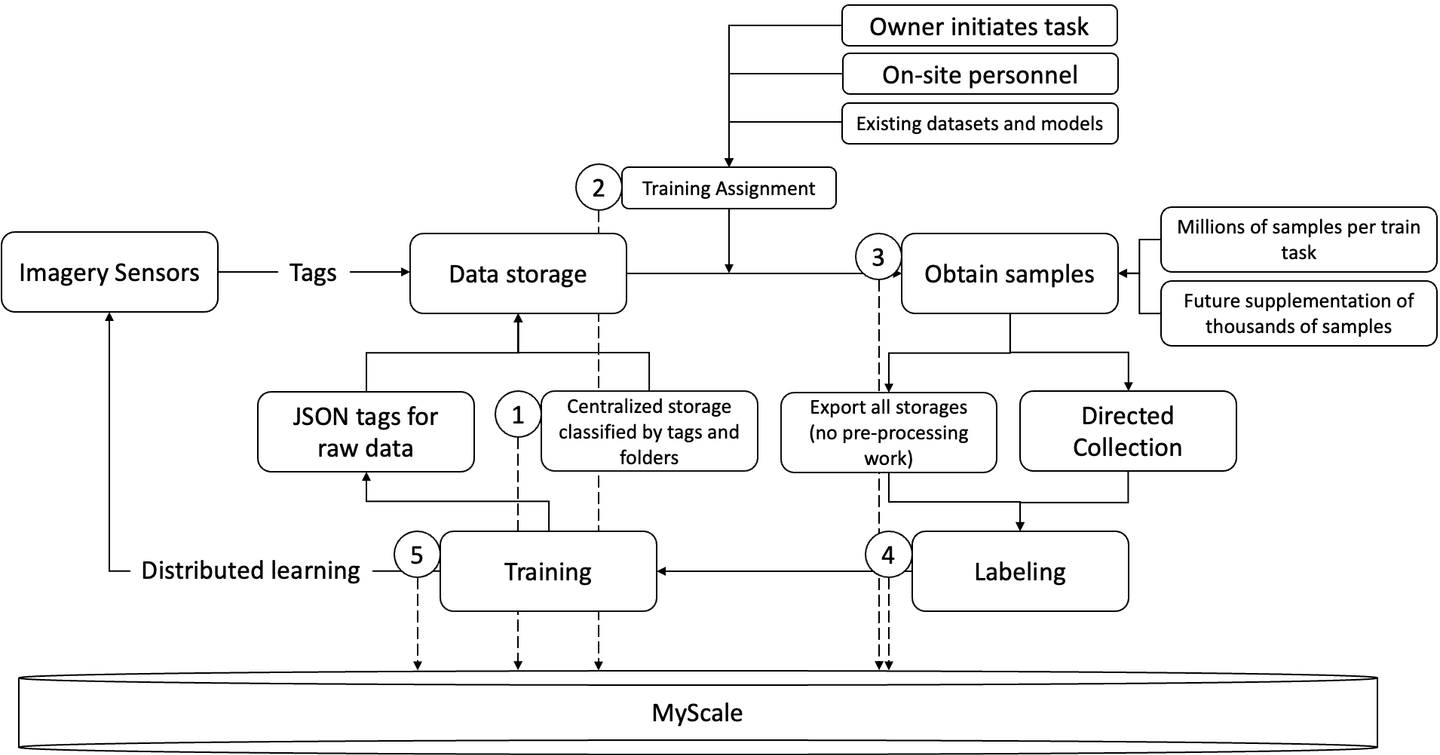
Cowarobot has used MyScale to improve their model training workflows for their autonomous vehicles, in areas ranging from storage to data labels and model training.
- Storing raw data and labels in a centralized storage
MyScale offers a unified storage for query and data management, with data types including ID, vector data, tag data, URL, and so on, making it easier to manage and use data sets for various purposes. This allows different departments within a business to better track their machine learning processes, improve their data usage, and broaden the scope of their training tasks.
- Executing training tasks
MyScale supports the rapid generation of training samples from stock data by allowing users to perform joint SQL queries (attribute filtering). As a result, new training tasks may require a smaller sample size or may not require the acquisition of new data at all. This reduces training costs and allows users to increase the frequency and types of training tasks with smaller datasets.
- Obtaining new samples
MyScale’s key advantage is that it only requires a small number of data samples. With fewer samples required, the workload of obtaining new samples required to train the model is reduced. MyScale accomplishes this by enabling users to run joint SQL queries to rapidly generate training samples from stored data. This is also useful if there is an existing database with a large number of samples, as MyScale can screen for training samples and look for higher quality training samples. This increases the precision of positive samples in labeled data.
- Data labels
MyScale require a small sample of data that have already been labeled to start the model training process. Data labeling takes less time and costs less money when there are fewer data samples that need to be changed by hand.
- Model training
MyScale can manage training data and provide full SQL support. MyScale lets users write simple SQL statements to directly create training samples. The model training can then call directly on the original data to start the process of training the model. This greatly simplifies the model training tasks and the way data is transmitted from various sources.

# How MyScale can help you in unlocking new business value from your video data

MyScale worked with robo-taxi company Cowarobot to manage their machine learning process that includes data collection, storage, acquisition labeling and model training for their autonomous fleet. A variety of data sources, including vector data and data annotations, are managed in an unified platform. The MyScale platform also offers full SQL support, which simplifies model training by requiring only a single query language.
MyScale also provides search capabilities for rapidly locating training samples from stored data. These cut down on the cost of training models and improves how often and how they are trained. Cowarobot utilized MyScale and few-shot learning to perform training data screening, data classification, and data marking. This strategy reduced the amount of required data annotation and data collection.
If your business is also dealing with images and videos in your current application, and would like to explore more on how MyScale can help extract more value from your applications and businesses, please don't hesitate to contact us at contact@myscale.com.



