
Retrieval-augmented generation (RAG) (opens new window) has been a major breakthrough in the domain of natural language processing (NLP). It has optimized most of the NLP tasks due to its simplicity and efficiency. By combining the strengths of retrieval systems (vector databases) and generative models (LLMs), RAG significantly enhances the performance of AI systems in areas such as text generation, translation and answering questions.
The integration of vector databases has been a key component in revolutionizing RAG systems' performance. Let’s explore the relationship between RAG and vector databases and how they have worked together to achieve such remarkable results.
# A Brief Overview on the RAG Model
RAG is a technique specifically designed to enhance the performance of large language models (LLMs). It retrieves information related to the user's query from vector databases and provides it to the LLM as a reference. This process significantly improves the quality of LLMs’ responses, making them more accurate and relevant. The following picture briefly shows how a RAG model works (opens new window).
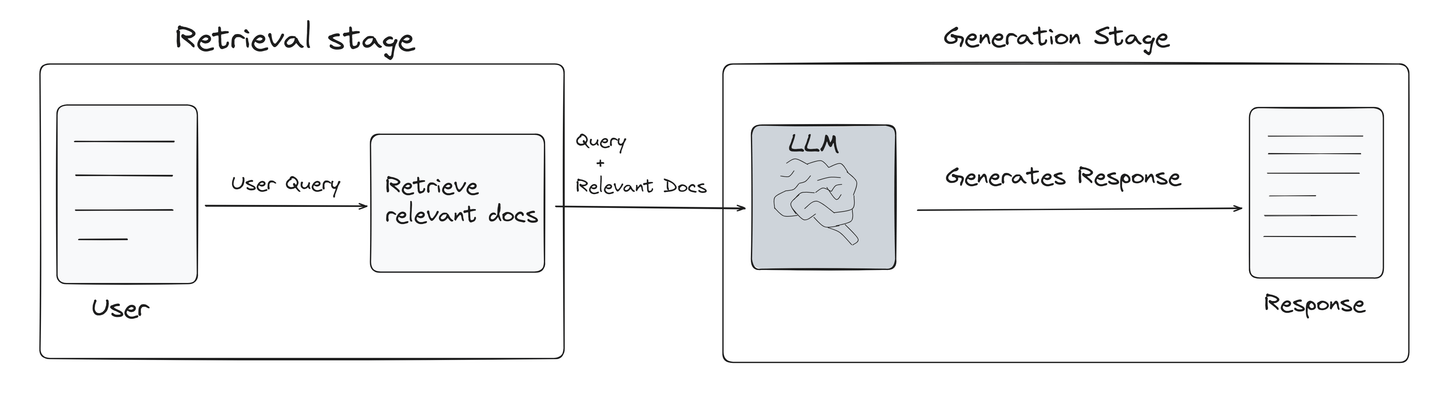
Retrieval stage: RAG first identifies the most relevant information from the vector database by using the power of similarity search. This stage is the most critical part of any RAG system as it sets the foundation for the quality of the final output.
Generation stage: Once the relevant information is retrieved, the user query along with the retrieved documents are passed to the LLM model to produce new content that is coherent, relevant and informative.
The implementation of RAG significantly improves the performance of LLMs by addressing key limitations such as factual inaccuracies, outdated knowledge and hallucination. The retrieval of relevant, up-to-date information from vector databases greatly enhances the accuracy and reliability of LLMs’ responses, particularly in knowledge-intensive tasks.
Moreover, it introduces a level of transparency and traceability, allowing users to verify the origins of the information provided. This hybrid approach of combining the generative capabilities of LLMs with the informative power of retrieval systems leads to more robust and trustworthy AI applications that can dynamically adapt to a wide range of complex queries and tasks.
# The Role of Vector Databases
A vector database is a specialized type of database designed to store and manage data in the form of numerical vectors, known as embeddings. These embeddings encode the semantic meanings and contextual information of any kind of data. The data could be text, images or even audio. Vector databases efficiently store these embeddings and provide rapid retrieval of embeddings through a similarity search. These features play an important role in tasks such as information retrieval, recommendation systems and semantic search. These databases are particularly useful in machine learning (ML) and artificial intelligence (AI) applications where data is often transformed into vector spaces to capture complex patterns and relationships.
Key features of vector databases include:
- High-dimensional data support: These databases are designed to handle high-dimensional vector data, which is commonly used in machine learning models.
- Efficient search: These databases provide optimized search algorithms to quickly find the most similar vectors from a vast dataset. The core search functionality is the nearest neighbor search, and all algorithms are designed to optimize this approach.
- Scalability: Vector databases are designed to handle large volumes of data and user queries. This makes them suitable for growing datasets and increasing demands.
- Indexing: These databases often use advanced indexing techniques to speed up the process of looking up and comparing vectors.
- Integration: They can be easily integrated with machine learning pipelines to provide real-time data retrieval capabilities.
Vector databases are a crucial component in systems that leverage machine learning for tasks such as image recognition, text analysis and recommendation algorithms, where the ability to quickly access and compare large sets of vectorized data is paramount.
# How Vector Databases Enhance RAG Performance
Vector databases significantly enhance the performance of RAG systems by optimizing various stages of the workflow. Initially, the textual data is converted into vectors using an embedding model. This conversion is important as it transforms textual data into a format that can be efficiently stored and retrieved based on semantic meanings.
The strength of a vector database lies in its advanced indexing methods. Once the data is converted into vectors, it is saved in the vector database using advanced indexing methods like HNSW (Hierarchical Navigable Small World) or IVF (Inverted File Index) (opens new window). These indexing methods organize the vectors in a way that allows for fast and efficient retrieval. The indexing process ensures that when a query is made, the system can quickly locate the relevant vectors from the vast dataset.
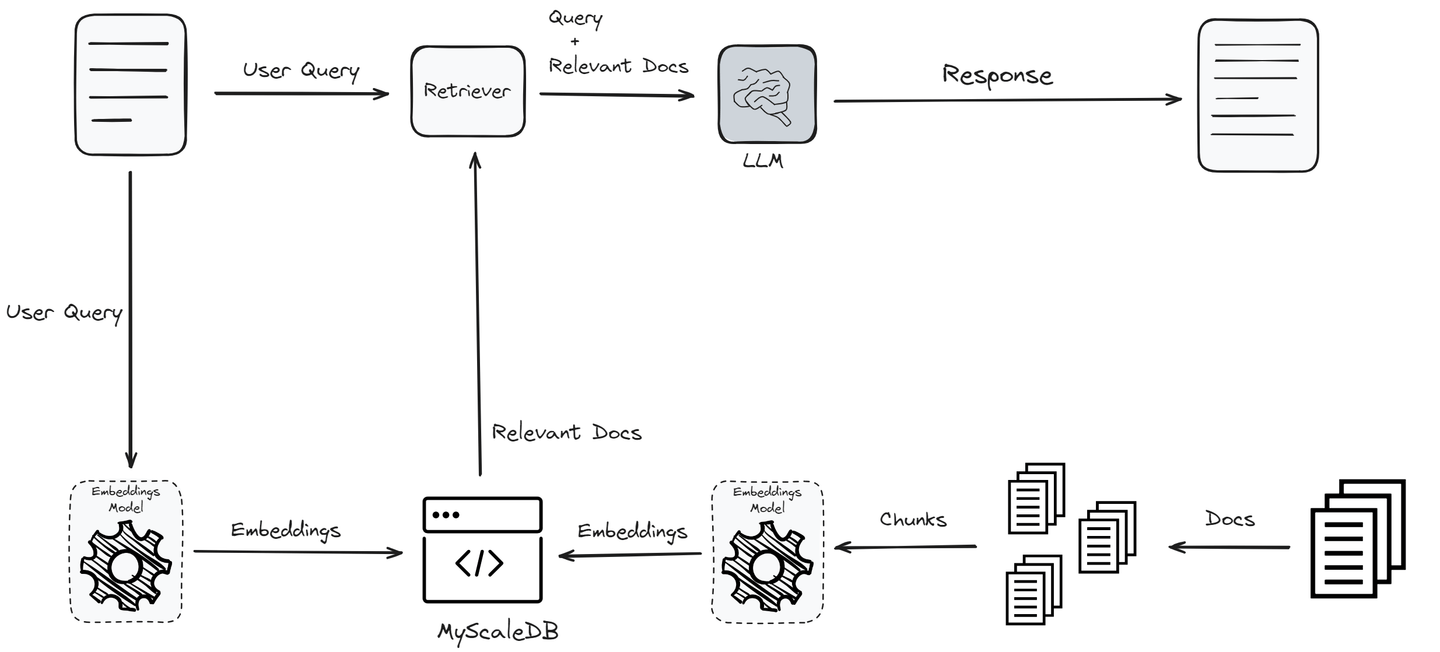
When a user submits a query, it is also converted into a vector using the same embedding model. The vector database looks for the nearest cluster with similar vectors. The vector database searches for clusters of vectors that are semantically closest to the query vector. This similarity search is the foundation of any RAG system and vector databases through rapid and accurate identification of semantically similar vectors.
The similar documents are then passed on to the retriever, which combines the query with the relevant documents and sends them to the LLM for response generation. The use of vector databases ensures that the retriever works with the most relevant information. This enhances the accuracy and relevance of the generated response.
Vector databases not only improve the retrieval speed but also handle large volumes of data efficiently. This scalability is essential for applications dealing with extensive datasets. By ensuring quick and precise retrieval, vector databases support real-time querying, providing users with immediate and relevant responses.

# The Ideal Solution: Specialized Vector Database vs. SQL Vector Database
In real-world RAG systems, overcoming retrieval accuracy (and the associated performance bottlenecks) requires an efficient way to combine querying of structured, vector and keyword data.
Some vector databases (like Pinecone, Weaviate and Milvus) are designed specifically for vector search from the outset. They exhibit good performance in this area but have somewhat limited general data management capabilities.
- Limited query capabilities: They provide limited support for complex queries, including those with multiple conditions, joins, and aggregations, due to restricted metadata storage.
- Data-type restrictions: Primarily designed for vector and minimal metadata storage, they lack the flexibility to handle various data types like integers, stringsand dates.
SQL vector database (opens new window) represent an advanced fusion of traditional SQL database functionalities with the specialized capabilities of vector databases. These systems integrate vector search algorithms directly into the structured data environment, enabling the management of both vector and structured data within a unified database framework.
This integration provides several key advantages:
- Streamlined communication between data types.
- Flexible filtering based on metadata.
- Support for executing both SQL and vector queries.
- Compatibility with existing tools designed for general-purpose databases.
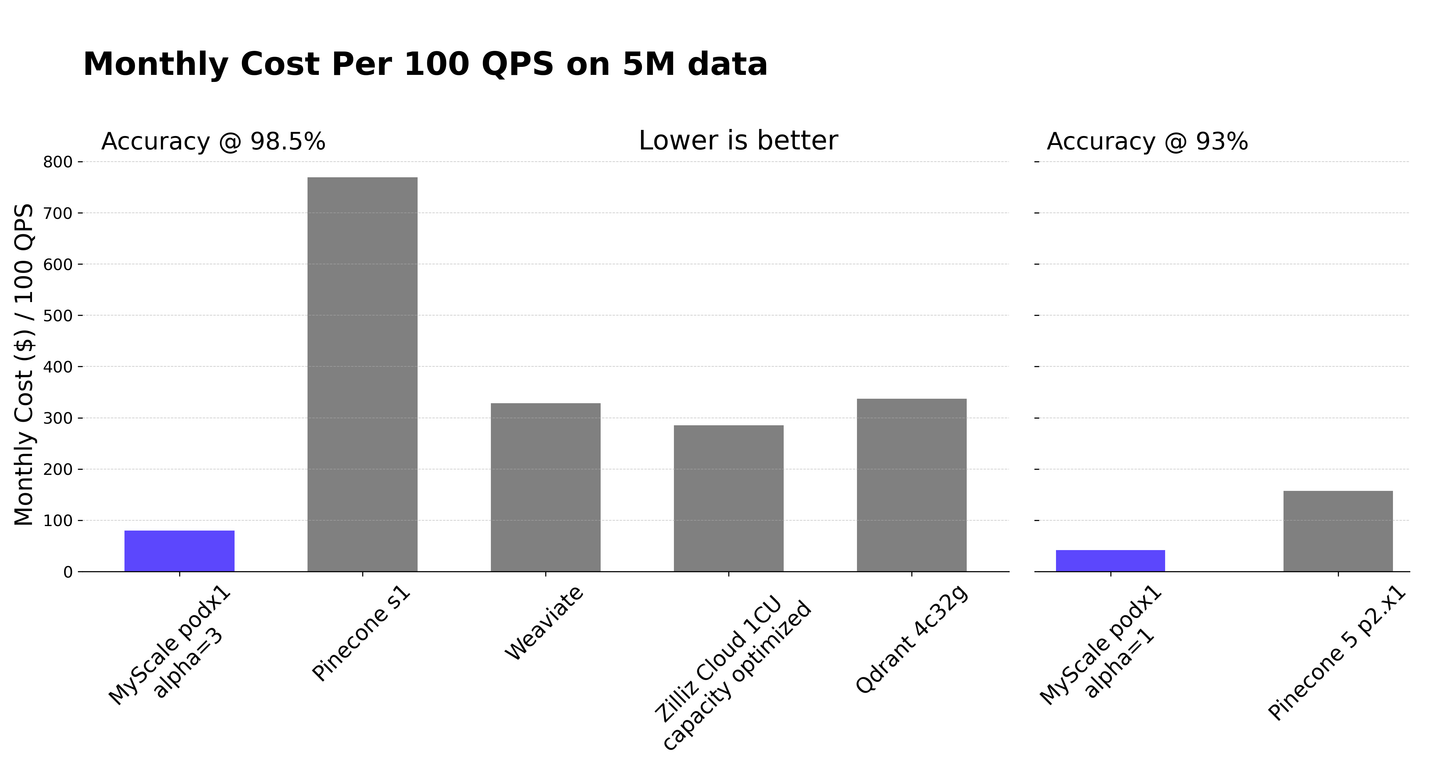
Among SQL vector databases, MyScaleDB (opens new window) is an open-source option that extends ClickHouse capabilities. It seamlessly combines structured data management with vector operations, optimizing performance for complex data interactions and enhancing the efficiency of RAG systems. With filtered searches (opens new window), MyScaleDB efficiently filters data in large datasets based on specific attributes before conducting vector searches, ensuring rapid and accurate retrieval for RAG systems.
# Conclusion
Vector databases have greatly enhanced RAG systems by optimizing data retrieval and processing. These databases enable efficient storage and quick retrieval based on semantic meaning. Advanced indexing methods like HNSW and IVF ensure that relevant data is swiftly located, enhancing the accuracy of responses. Furthermore, vector databases handle large volumes of data, providing the necessary scalability for real-time querying and immediate user responses.
A SQL vector database takes these advantages further by integrating vector search with SQL. This allows for complex and precise data interactions. This integration simplifies development and reduces the learning curve for building robust RAG applications.
You are welcome to explore the open-source MyScaleDB repository on GitHub (opens new window), and leverage SQL and vectors to build innovative, production-level RAG applications.
This article is originally published on The New Stack. (opens new window)



