
Vector search can rapidly locate semantically similar or related candidates within massive amounts of text, images, and other data. However, in real-world scenarios, pure vector search is often insufficient.
Actual data usually includes attributes like time, category, user ID, and other keywords. Applying one or more filtering conditions to these attributes can significantly improve the precision of Retrieval-Augmented Generation (RAG) systems as well as form the basis of large-scale multi-tenant systems. MyScale (opens new window), developed on ClickHouse database, supports a wide range of data types of SQL, achieves high precision and efficiency in searches with any filtering ratio.
This article discusses the importance of filtered vector search, as well as the technologies behind implementing it, including pre-filtering and post-filtering, as well as row and column storage.
# Filtered Vector Search is Essential for Improving the Accuracy of RAG Systems
Filtered search plays a vital role in supporting high-accuracy LLM/AI applications. Pure vector retrieval often yields relatively accurate candidates in scenarios with limited document content. However, as the document volume increases, the recall rate of retrieval typically decreases rapidly.
This issue mainly arises in complex document environments like finance, where relevant content is often abundant. In these cases, pure vector retrieval can return many similar but incorrect paragraphs, negatively impacting the accuracy of the final response.
For instance, in financial analysis scenarios, a user might ask: "What's the management style of <Company>?" When <Company> is a less common company name, pure vector retrieval can often lead to a multitude of similar but inaccurate content, such as paragraphs about the management style of similar companies, which hinders the accurate generation of responses by the LLM.
However, suppose we know in advance that document titles related to <Company> include this keyword in their titles, we can use WHERE title ILIKE '%<Company>%' for pre-filtering, thereby narrowing the search results to only relevant documents. Additionally, the <Company> can be automatically extracted by the LLM—e.g., as a parameter in a function call or generating SQL WHERE clauses from the query text—ensuring the system is flexible and easy to use.
By employing these structured attributes for filtering, we have observed a precision increase from 60% to 90% in real-world applications like financial document analysis and enterprise knowledge bases. Therefore, to ensure high-precision queries within RAG systems, we need a flexible and universal approach to structured + vector data modeling and querying, as well as vector retrieval that guarantees high precision and efficiency regardless of the filtering ratio.

# Filtered Vector Search is the Foundation for Implementing Large-Scale Multi-User Systems
Filtered vector search is fundamental in applications like large-scale document QA, virtual character chat with semantic memory, and social networking, where the system needs to support queries on data from millions of users, with each query typically involving data from a single or small set of users.
This demands exceptionally high query precision at very low filtering ratios on a large vector dataset. Specialized vector databases like Pinecone, Weaviate, and Milvus, designed for such applications, have introduced a namespace mechanism where developers can place each user's data in a separate namespace, ensuring query precision.
However, this approach limits flexibility, as a single query can only search within one namespace. For example, in social networks, users might need to query content related to their friends, involving queries for hundreds to thousands of friends' data. Complex filtered queries are often required in context analysis and recommendation systems—based on time, author, keywords, etc.
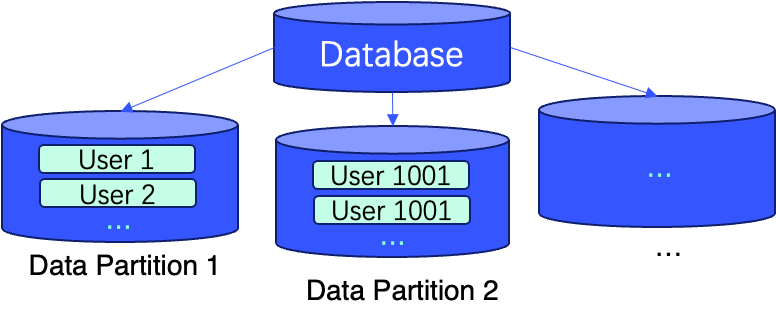
In these cases—and more—using WHERE conditions for filtered queries provides a more flexible approach. Moreover, employing data partitioning and sorting data via primary keys can further enhance query efficiency by improving data locality.
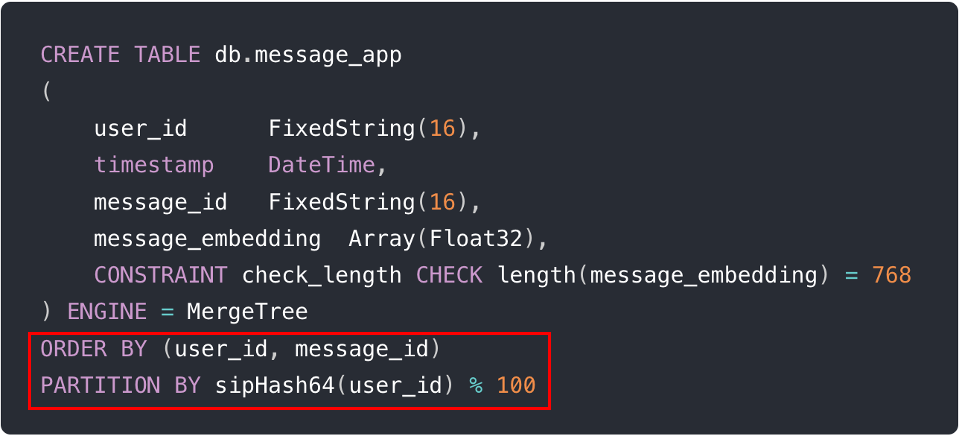
The following figures describe a real-world example showing the implementation of these techniques with two lines of SQL during table creation (i.e., ORDER BY (user_id, message_id) and PARTITION BY sipHash64(user_id) % 100).
Note:
See our multi-tenancy documentation (opens new window) for more details.
# MyScale Supports High-Precision, High-Efficiency Filtered Search at Any Ratio
MyScale achieves high-precision, highly efficient filtered search at any filtering ratio by combining columnar storage, pre-filtering, and efficient search algorithms. It offers a 4x-10x lower cost-per-QPS ratio compared to other products.
For instance, MyScale achieves the highest search speed and precision in our open-source benchmark (opens new window), outperforming similar systems that fall short in precision and speed while being up to 5x cheaper. This precise and efficient filtered search capability is a crucial foundation for production-grade RAG systems.
Note:
For more results, refer to the comparative article on MyScale vs. pgvector and OpenSearch (opens new window).
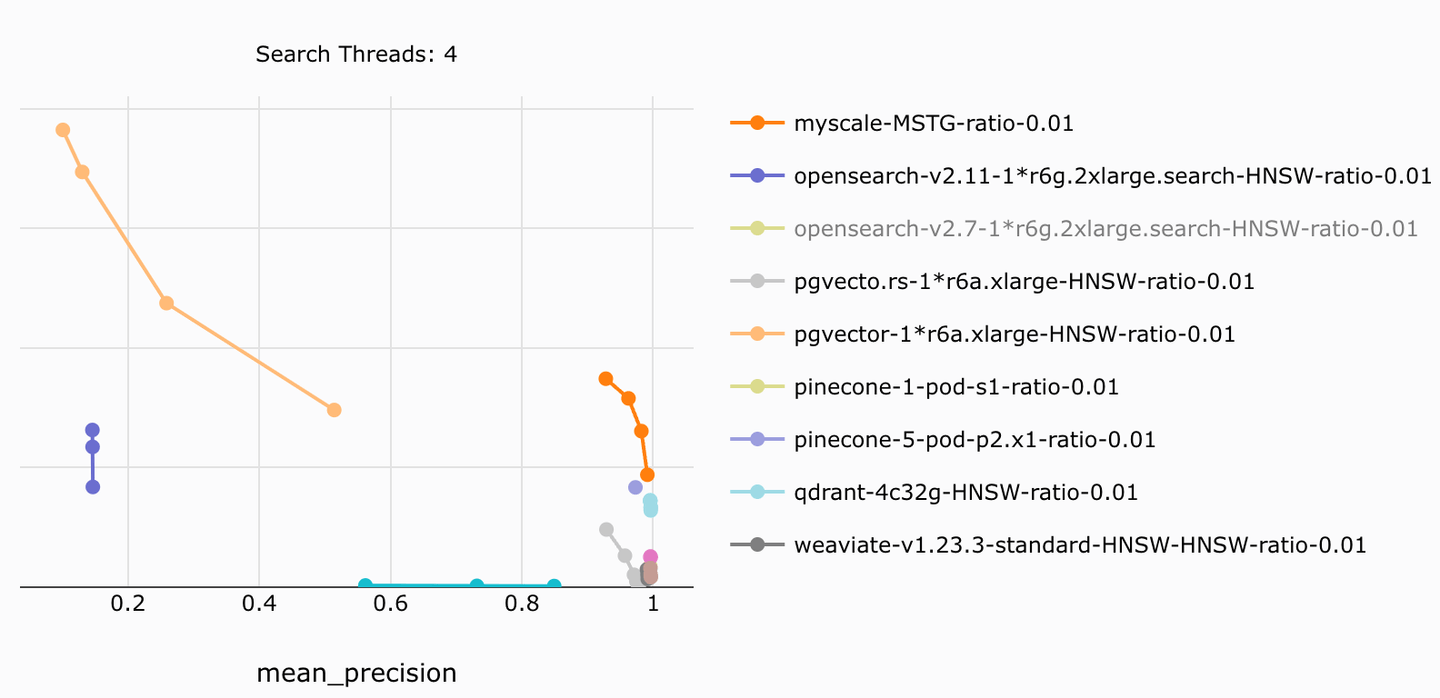
As highlighted above, MyScale is developed based on the widely used ClickHouse SQL database, supporting a wide range of data types and functions (opens new window), such as numeric, datetime, geospatial, JSON, string, and so on. This signficantly improves the filtering query capabilities compared to specialized vector databases like Pinecone, Weaviate, and Qdrant.
Furthermore, since LLMs are highly proficient in SQL, they can automatically convert natural language into SQL WHERE conditions. This means that users without technical backgrounds can execute filtered queries using natural language, further improving the flexibility and precision of RAG systems. We have implemented similar technology in the LangChain MyScale Self-Query (opens new window), which has been widely applied in production systems.

# Behind the Scene
Despite the importance of filtered vector searches in many scenarios, implementing precise and efficient filtered vector searches involves numerous technical detailed choices, such as pre- vs. post-filtering, columnar vs. row storage, and graph vs. tree algorithms (opens new window). By integrating technologies like pre-filtering, columnar storage, and multi-scale tree-graph algorithms, MyScale has achieved outstanding accuracy and speed in filtered vector search.
# Pre-Filtering vs. Post-Filtering
There are two approaches to implementing metadata filtering in filtered vector search: pre-filtering and post-filtering.
Pre-filtering first selects vectors that meet the criteria using metadata and then searches these vectors. The advantage of this method is that if users need k most similar documents, the database can guarantee k results.
Post-filtering, on the other hand, involves performing a vector search first to obtain m results and then applying metadata filters to these results. The drawback of this method is the uncertainty of how many of the m results meet the metadata filter criteria, potentially resulting in fewer than k final results. When the vectors meeting the filter criteria are scarce, post-filtering accuracy significantly decreases. PostgreSQL’s vector retrieval plugin, pgvector, adopts this approach, suffering significant accuracy loss when the ratio of qualifying data is low.
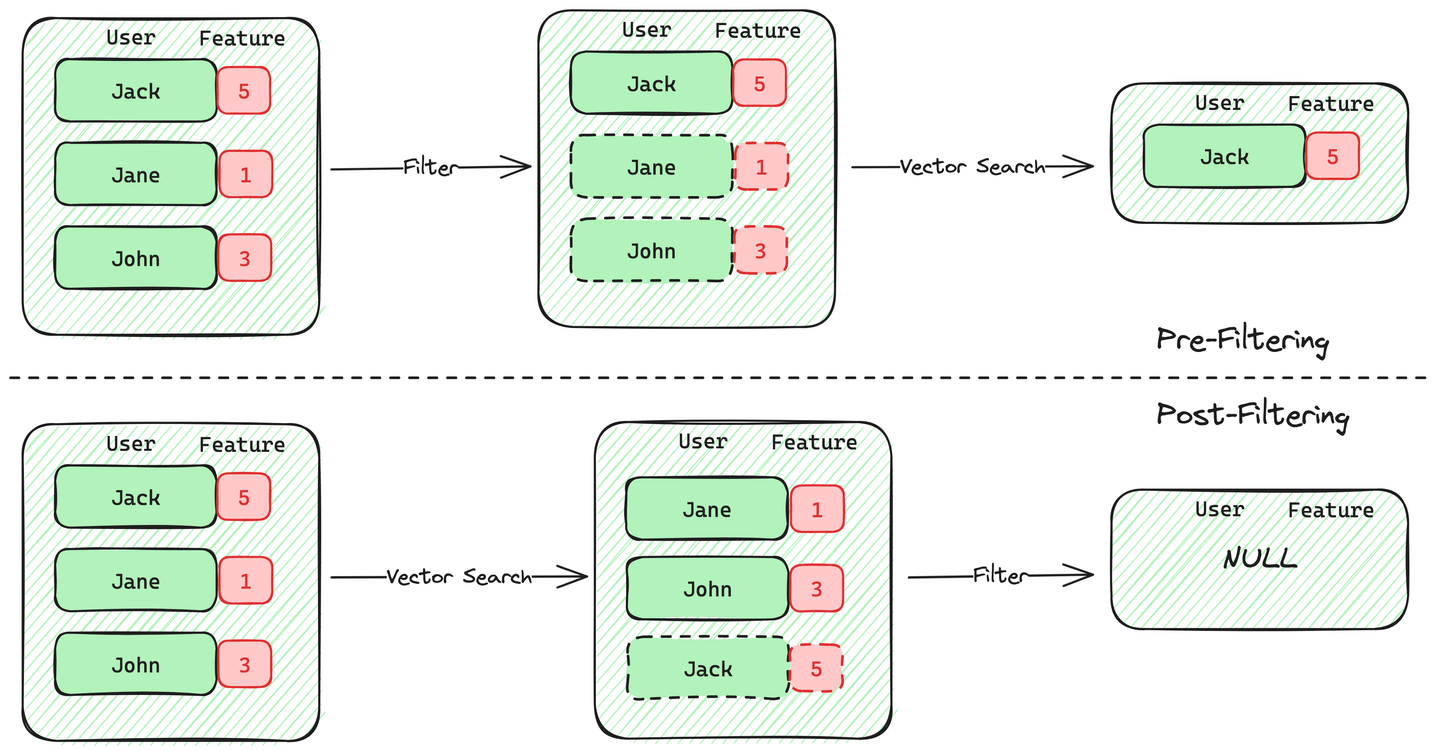
The challenge with pre-filtering lies in efficiently filtering data and maintaining search efficiency in vector indexes when the number of qualifying vectors is small.
For instance, the widely used HNSW (Hierarchical Navigable Small World) algorithm experiences a significant drop in search effectiveness when the filtering ratio is low—e.g., only 1% of vectors remain after filtering. To address this issue, a common industry-wide solution is to resort to brute-force search when the filtering ratio falls below a specific threshold.
Pinecone, Milvus, and ElasticSearch, for example, all employ this method, but it can, however, severely impact performance with large datasets. MyScale, on the other hand, ensures high accuracy and efficiency at any filtering ratio by combining highly efficient pre-filtering with algorithmic innovations.
# Row-Based vs. Column-Based Storage
When adopting a pre-filtering strategy, efficiently scanning metadata is critical to retrieval performance. Database storage is generally categorized as either row-based or column-based.
Row-based storage is typically used in transactional databases—like MySQL or PostgreSQL—and is more friendly to point reads and writes, especially for transaction processing. Juxtapositionally, column-based databases (like ClickHouse) are highly efficient for analytical processing, especially for scanning several columns of data, batch data ingestion, and compressed storage.
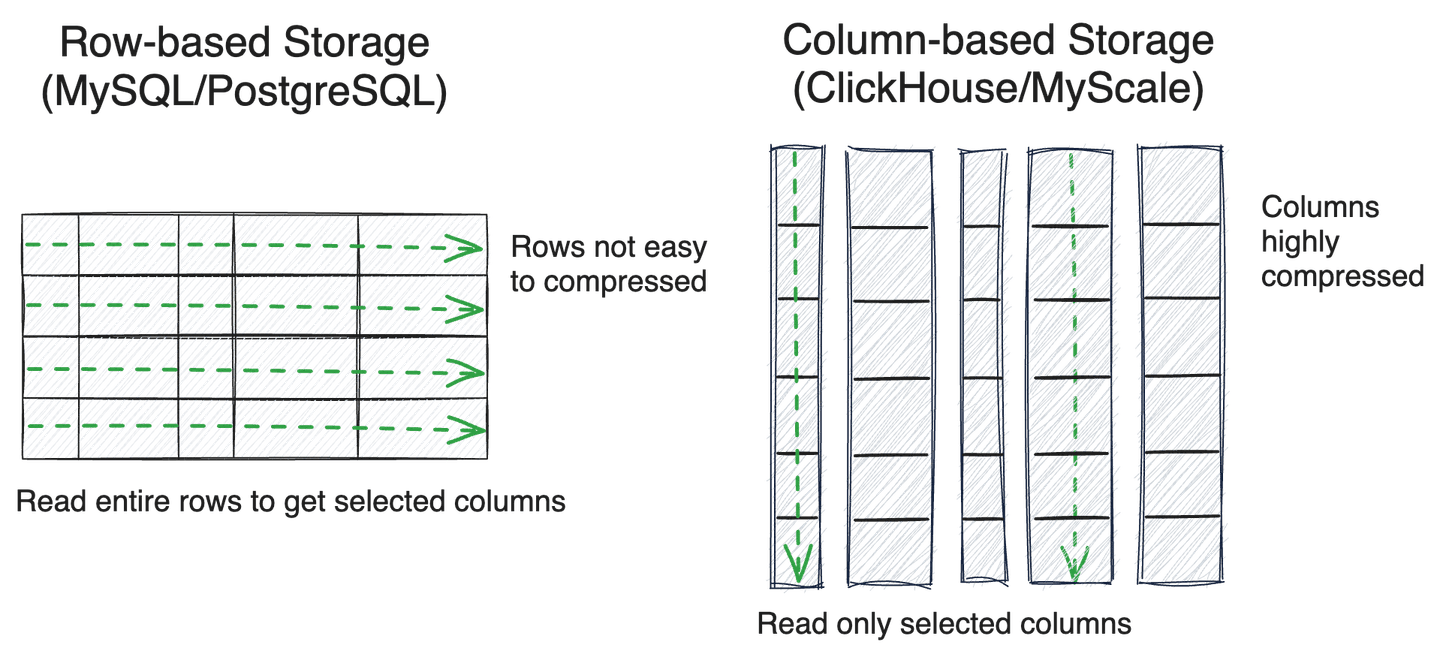
Due to the need for efficient metadata scanning, many specialized vector databases, such as Milvus and Qdrant, have also adopted columnar storage. After years of optimization on massive, structured data analytical queries, columnar SQL databases like ClickHouse—see ClickBench (opens new window) for more information—stand out even more, using techniques such as skip indexes and SIMD operations, significantly improving data scanning efficiencies throughout many practical scenarios.
Through extensive user research, we found that in AI/LLM applications like RAG have less need for small write transactions, but efficient data scanning and analysis are imperative. Therefore, for us, columnar storage is a more suitable choice.
This is a key reason why MyScale chose to develop based on ClickHouse. Correspondingly, systems like pgvector and pgvecto.rs, due to the limitations of PostgreSQL's row-based storage, face issues with filtered search accuracy or speed.
Lastly, the most significant challenge with columnar databases is that their multi-column point reads are inefficient—due to data read amplification and decompression overhead. The good news is that this can be addressed using technologies such as uncompressed data caching. There is also a lot of room for improvement in the joint querying of structured and vector data, such as the relaxed monotonicity optimizations in vbase (opens new window).
# Summary
By combining structured and vector data in one query, filtered vector search has widespread and significant applications in advanced RAG systems, large-scale multi-user systems, and more. MyScale, built on the columnar-based ClickHouse SQL database, supports a rich array of metadata types and functions, together with flexible self-query capabilities.
By employing pre-filtering, columnar storage, and algorithmic optimizations, MyScale achieves high accuracy and speed in filtered search at any filtering ratio, laying a solid data foundation for LLM applications.
If you have more thoughts about filtered searches or wish to share your ideas, please follow us on Twitter (opens new window) and join our Discord (opens new window) community.



