
Large Language Models (LLM) can be more reliable on truthfulness when given some retrieved contexts from a knowledge base, which is known as Retrieval Augmented Generation (RAG). Our earlier blogs discussed RAG's performance gain (opens new window) and feasibility in cost and latency (opens new window). In this blog, we will bring you an advanced usage to the RAG pipeline: building a chatbot using Retrieval Augmented Generation with MyScale. You can also try it on our huggingface space (opens new window)
Note:
Visit MyScale's HuggingFace space (opens new window) to try out our chatbot.
![]()
Chatbots differ from single-turn question and answer tasks. Here’s how:
Single-turn Q&A tasks:
In single-turn question-and-answer tasks, the interaction between the user and system typically consists of a single question posed by a user and a straightforward answer provided by the system. These are known as question-and-answer pairs.
Chatbots:
However, the conversation between a chatbot and a user is more complex and extended with multi-turn discussions. Chatbots can handle ongoing dialogues and follow-up questions, following the conversation's context across multiple interactions.
In order to achieve this, the chatbot needs to store a user's total chat history, including its previous conversations and actions (or results) from their last function calls. Secondly, the chatbot's memory should be able to serve different users simultaneously, keeping their conversations separate from each other. This can be a significant challenge if not set up correctly. The good news is that MyScale provides a perfect solution to this challenge through its SQL compatibility and role-based access control (opens new window) functionality, allowing you to manage millions of users' chat histories easily.
Chatbots can also benefit from RAG, but not every chat needs RAG. For instance, when the user asks for a translation from one language to another, adding RAG into the mix will not add value to this request. Consequently, we must let the chatbot decide when and where to use RAG as part of its search query.
How do we achieve this?
Fortunately, OpenAI has a function call API that we can use to insert a retrieval pipeline with MyScale as an external function call (opens new window).
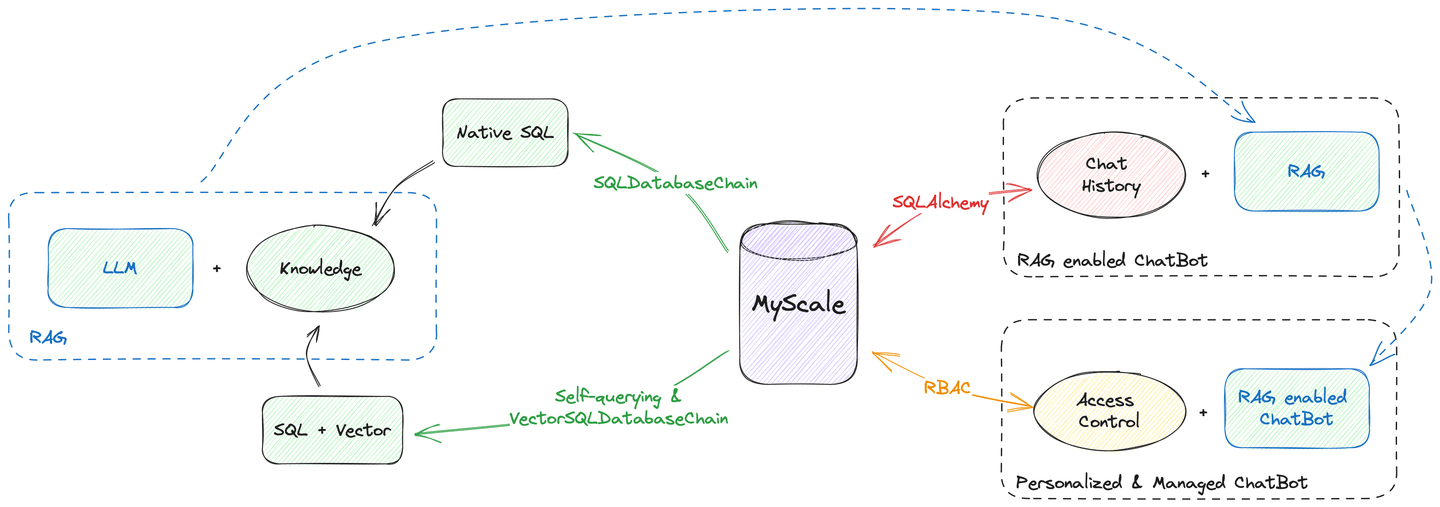
Moreover, MyScale is capable of doing all the data hosting jobs, from vector search to chat history management. As the diagram above demonstrates, you can build a chatbot using MyScale as your only data source. You don't need to worry about your data being scattered across different databases and engines.
So, let's see how it is done!
# Retriever-as-a-Tool
RAG can be symbolized as an external function. See our OpenAI function call documents (opens new window) for more information on creating a prompt to teach GPT to use the MyScale vector store as a tool.
Today, we will use LangChain’s retriever APIs rather than the vectorstore to augment your query using MyScale’s advanced filter search. Previously, we showed how self-querying retrievers (opens new window) can translate your questions into vector search queries using filters. We also described how retrievers built from vector SQL database chain (opens new window) do the same thing as self-querying retrievers but in an SQL interface.
Note:
These two retrievers take only query text as input, so converting them into chatbot tools is easy.
Actually, it just takes a few lines of code to transform a retriever into a tool:
from langchain.agents.agent_toolkits import create_retriever_tool
retriever = ... # self-querying retriever / vector SQL database retriever
# Create a tool with proper description, taking Wikipedia retrieval as an example:
tool = create_retriever_tool(retriever,
"search_among_wikipedia",
"Searches among Wikipedia and returns related wiki pages")
# create toolset
tools = [tool]
Therefore, you can create multiple tools and feed them to a single chatbot. For example, if you have numerous knowledge bases to search, you can develop tools for every knowledge base and let the chatbot decide which tool to use.
# Remembering the Chats
Chat memories are crucial to chatbots. Because we provide our chatbot with multiple tools, we also need to provide memory to store the intermediate results from these tools. This requires rich data type and advanced multi-tenancy support, which MyScale is good at.
The following Python script describes how to create memory for the chatbot:
from langchain.memory import SQLChatMessageHistory
from langchain.memory.chat_message_histories.sql import BaseMessageConverter, DefaultMessageConverter
from langchain.agents.openai_functions_agent.agent_token_buffer_memory import AgentTokenBufferMemory
# MyScale credentials
MYSCALE_USER = ...
MYSCALE_PASSWORD = ...
MYSCALE_HOST = ...
MYSCALE_PORT = ...
database = 'chat'
# MyScale supports sqlalchemy via package `clickhouse-sqlalchemy`
conn_str = f'clickhouse://{MYSCALE_USER}:{MYSCALE_PASSWORD}@{MYSCALE_HOST}:{MYSCALE_PORT}'
# LangChain has native support to SQL database as chat history backend
chat_memory = SQLChatMessageHistory(
# session ID should be user-specific, it isolates sessions
session_id,
# MyScale SaaS is using HTTPS connection
connection_string=f'{conn_str}/{database}?protocol=https',
# Here we customized the message converter and table schema
custom_message_converter=DefaultClickhouseMessageConverter(name))
# AgentTokenBufferMemory will help us store all intermediate messages from users, bots and tools
memory = AgentTokenBufferMemory(llm=llm, chat_memory=chat_memory)
MyScale also functions as a relational database. And thanks to LangChain's SQLChatMessageHistory, you can use MyScale as your memory backend via clickhouse-sqlalchemy. A customized message converter is needed to store more information in the database.
Here is how you can define the memory's table schema:
import time
import json
import hashlib
from sqlalchemy import Column, Text
try:
from sqlalchemy.orm import declarative_base
except ImportError:
from sqlalchemy.ext.declarative import declarative_base
from clickhouse_sqlalchemy import types, engines
from langchain.schema.messages import BaseMessage, _message_to_dict, messages_from_dict
def create_message_model(table_name, DynamicBase): # type: ignore
# Model declared inside a function to have a dynamic table name
class Message(DynamicBase):
__tablename__ = table_name
# SQLChatMessageHistory will order messages by id
# So here we store timestamp as id
id = Column(types.Float64)
# session id is to isolate sessions
session_id = Column(Text)
# This is the real primary key for the message
msg_id = Column(Text, primary_key=True)
# type to this message, could be HumanMessage / AIMessage or others
type = Column(Text)
# Additional message in JSON string
addtionals = Column(Text)
# message in the text
message = Column(Text)
__table_args__ = (
# ReplacingMergeTree will deduplicate w.r.t primary key
engines.ReplacingMergeTree(
partition_by='session_id',
order_by=('id', 'msg_id')),
{'comment': 'Store Chat History'}
)
return Message
class DefaultClickhouseMessageConverter(DefaultMessageConverter):
"""A ClickHouse message converter for SQLChatMessageHistory."""
def __init__(self, table_name: str):
# create table schema for chat memory
self.model_class = create_message_model(table_name, declarative_base())
def to_sql_model(self, message: BaseMessage, session_id: str) -> Any:
tstamp = time.time()
msg_id = hashlib.sha256(f"{session_id}_{message}_{tstamp}".encode('utf-8')).hexdigest()
# fill out the blanks
return self.model_class(
id=tstamp,
msg_id=msg_id,
session_id=session_id,
type=message.type,
addtionals=json.dumps(message.additional_kwargs),
message=json.dumps({
"type": message.type,
"additional_kwargs": {"timestamp": tstamp},
"data": message.dict()})
)
def from_sql_model(self, sql_message: Any) -> BaseMessage:
# convert retrieved history as a message object
msg_dump = json.loads(sql_message.message)
msg = messages_from_dict([msg_dump])[0]
msg.additional_kwargs = msg_dump["additional_kwargs"]
return msg
Now, you have a fully functional chat memory backed by MyScale. Hooray!
# Chat Memory Management
User conversation histories are assets, and they must be kept safe. LangChain's chat memories already have session isolation controlled by session_id (opens new window).
Millions of users might interact with your chatbot, making memory management challenging. Fortunately, we have several "tricks" to help manage chat histories for all these users.
MyScale supports data isolation by creating different tables, partitions, or primary keys for users. As having too many tables in the database will overload the system, we encourage you to adopt a metadata-filtering-oriented multi-tenancy strategy (opens new window) instead. To be more concrete, you can create partitions instead of tables for your users or order them using a primary key. This will help you to perform fast retrieval from your database, which is more efficient than searching and storing.
In this scenario, we recommend using the primary-key-based solution. Adding session_id to the list of primary keys will improve the speed when retrieving a specific user's chat history.
# Here we modify the SQLAlchemy model
def create_message_model(table_name, DynamicBase): # type: ignore
class Message(DynamicBase):
__tablename__ = table_name
id = Column(types.Float64)
session_id = Column(Text, primary_key=True)
msg_id = Column(Text, primary_key=True)
type = Column(Text)
addtionals = Column(Text)
message = Column(Text)
__table_args__ = (
engines.ReplacingMergeTree(
# ||| This will create partitions for every 1,000 sessions
# vvv (too many partitions will drag the system)
partition_by='sipHash64(session_id) % 1000',
# Here we order by session id and message id
# so it will speed up the retrieval
order_by=('session_id', 'msg_id')),
{'comment': 'Store Chat History'}
)
return Message
Note:
See our documentation if you want to learn more about multi-tenancy strategies (opens new window).
# Putting Them Together
We now have all the components needed to build a chatbot with RAG. Let's put them together, as the following code snippet describes:
from langchain.agents import AgentExecutor
from langchain.schema import SystemMessage
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import MessagesPlaceholder
from langchain.agents.openai_functions_agent.base import OpenAIFunctionsAgent
# initialize openai llm
chat_model_name = "gpt-3.5-turbo"
OPENAI_API_BASE = ...
OPENAI_API_KEY = ...
# create llm
chat_llm = ChatOpenAI(model_name=chat_model_name, temperature=0.6, openai_api_base=OPENAI_API_BASE, openai_api_key=OPENAI_API_KEY)
# starting prompts to encourage the chatbot to use search functions
_system_message = SystemMessage(
content=(
"Do your best to answer the questions. "
"Feel free to use any tools available to look up "
"relevant information. Please keep all details in the query "
"when calling search functions."
)
)
# create function call prompts
prompt = OpenAIFunctionsAgent.create_prompt(
system_message=_system_message,
# This is where you place chat history from the database
extra_prompt_messages=[MessagesPlaceholde(variable_name="history")],
)
# We use the OpenAI function agent
agent = OpenAIFunctionsAgent(llm=chat_llm, tools=tools, prompt=prompt)
# combine all components together
executor = AgentExecutor(
agent=agent,
tools=tools,
memory=memory,
verbose=True,
# We store all those intermediate steps in the database, so we need this
return_intermediate_steps=True,
)
There you have it: A RAG-enabled chatbot with an AgentExecutor. You can talk to it with a simple line of code:
response = executor({"input": "hello there!"})
Note: All chat histories are stored under executor.memory.chat_memory.messages. If you want a reference on rendering messages from memory, please refer to our implementation on GitHub (opens new window).

# To Conclude...
MyScale is really good at high-performance vector search and provides all the functionality that SQL databases offer. You can use it as a vector database and an SQL Database. Moreover, it has advanced features like access control to manage your users and apps.
This blog demonstrates how to build a chatbot with MyScale, using it as the only data source. Integrating your chatbot with a single database ensures data integrity, security, and consistency. It also reduces data redundancy by storing references to records, improving data access, and sharing with advanced access control. This can significantly enhance reliability and quality, making your chatbot a modernized service that can scale up as large as your business needs.
Try our chatbot out on huggingface (opens new window), or run it yourself using code from GitHub (opens new window)! Also, join us to share your thoughts on Twitter (opens new window) and Discord (opens new window).
# References:
- https://myscale.com/blog/teach-your-llm-vector-sql/ (opens new window)
- https://myscale.com/docs/en/advanced-applications/chatdata/ (opens new window)
- https://myscale.com/docs/en/sample-applications/openai-function-call/ (opens new window)
- https://python.langchain.com/docs/modules/memory/ (opens new window)
- https://python.langchain.com/docs/integrations/memory/sql_chat_message_history (opens new window)
- https://python.langchain.com/docs/use_cases/chatbots (opens new window)
- https://python.langchain.com/docs/use_cases/question_answering/how_to/conversational_retrieval_agents (opens new window)



