
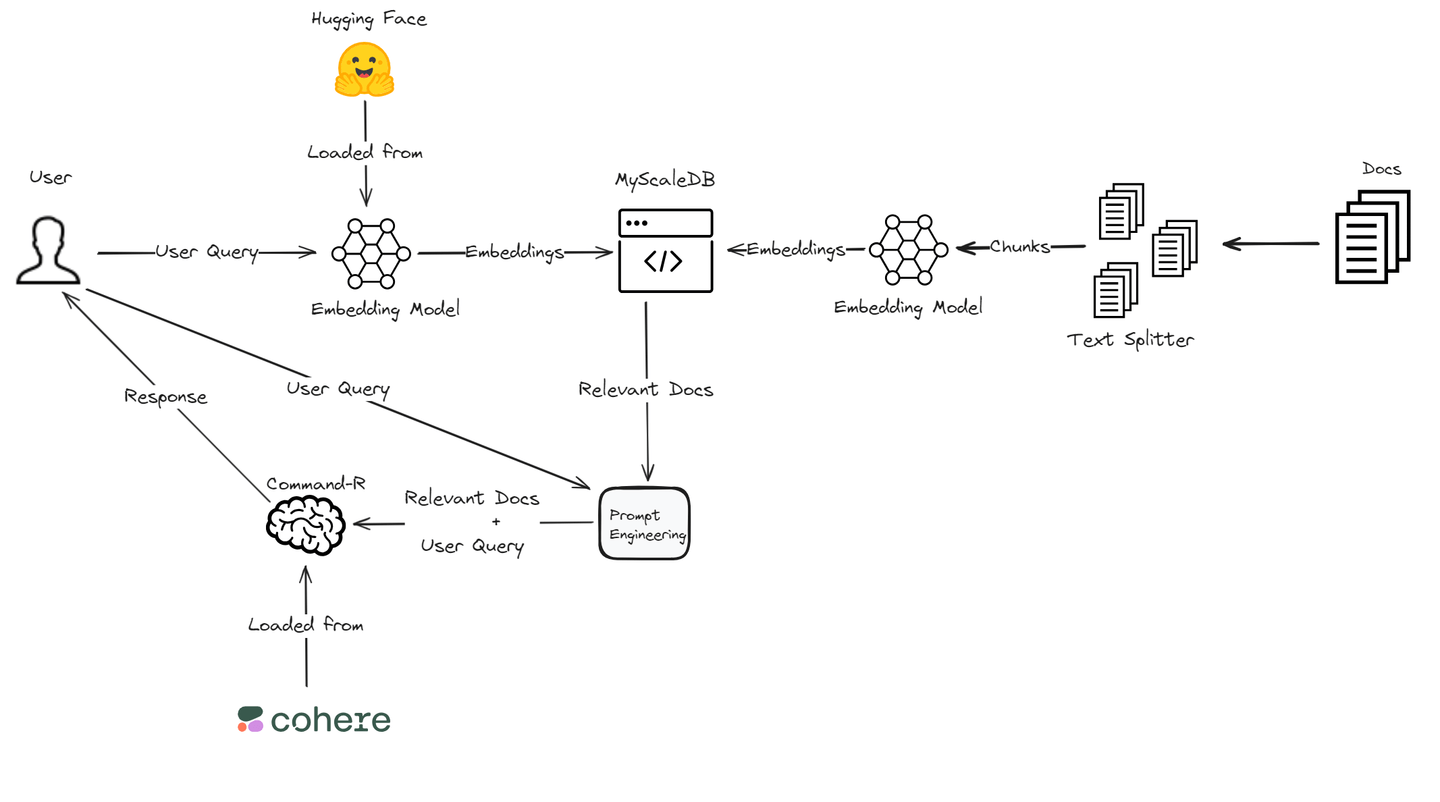
Retrieval-Augmented Generation (RAG) (opens new window) is a technique that enhances the output of large language models by referencing external knowledge sources. This approach ensures more accurate and contextually relevant responses without the need for retraining the model. It's a cost-effective way to boost the performance of language models in various domains.
In this blog, we will build an RAG application using Cohere's Command R model (opens new window) due to its superior performance in RAG. It provides high accuracy in retrieving and generating relevant information. For embeddings (opens new window), we will rely on Hugging Face's Transformers library (opens new window), which offers extensive support for various NLP tasks and integrates well with deep learning frameworks. Moreover, the high-performance and cost-efficient MyScaleDB will be used to store the embeddings and text chunks. This technical combination ensures a powerful and efficient RAG system, tailored to meet our specific application needs.
# What is Cohere?
Cohere (opens new window) is a platform specializing in developing advanced language models to help businesses automate and enhance customer interactions. They offer state-of-the-art large language models (LLMs) such as Command, which supports applications like conversational agents and summarization, and Rerank, which optimizes search result relevance. These tools improve communication efficiency and accuracy for companies.
In addition to their primary LLMs, Cohere provides models like Embed for tasks such as text classification and semantic search, and RAG capabilities to integrate and retrieve information from documents and enterprise data sources. These models enable businesses to deploy secure, scalable AI solutions, enhancing their overall operational efficiency and customer experience.
# What is Hugging Face?
Hugging Face (opens new window) is a platform known for its advanced language models, specializing in making state-of-the-art machine learning accessible to a wide audience. Their core product, the Transformers library, is open-source and supports tasks like text generation, summarization, and translation. This library is compatible with popular deep learning frameworks such as PyTorch and TensorFlow, allowing users to easily implement cutting-edge NLP models like BERT and GPT-2.
In addition to providing powerful NLP tools, Hugging Face offers various no-code and low-code solutions for deploying generative AI models. Their platform includes features like Inference Endpoints for easy model deployment and Spaces for hosting machine learning applications. Hugging Face also supports collaboration through its Model Hub, where users can share and access thousands of models, datasets, and applications. This community-driven approach helps democratize machine learning and foster innovation in the AI field.
# Building Blocks of an RAG Application with Cohere and Hugging Face
Let's delve into the essential components for constructing a robust RAG Application using Cohere and Hugging Face.
# Integrating Cohere's Command-R Model
When using Cohere for your RAG application, an important feature is the Command-R Model. This model improves retrieval-augmented generation by connecting with external data sources to fetch relevant information, which boosts the relevance and accuracy (opens new window) of the responses. By using this feature, your application can deliver more insightful and contextually appropriate answers.
# Accessing Pre-trained Models with Hugging Face
Incorporating Hugging Face's Pre-trained Models into your RAG Application provides a significant advantage in terms of efficiency and accuracy. These models come equipped with extensive training on diverse datasets, enabling them to generate high-quality responses across various domains. By tapping into these pre-trained models, you can expedite the development process while maintaining a high standard of output quality.
Note:
To utilize Hugging Face models in your project, first create an account on Hugging Face and obtain the Access Token (opens new window).
# Setting Up Your Environment
To embark on your RAG Application journey, ensure you have the necessary tools and accounts ready. You'll need access to platforms like Cohere and Hugging Face, along with accounts on these platforms. Additionally, installing essential libraries such as Cohere's API and Hugging Face Transformers will be crucial for seamless integration.
pip install cohere transformers clickhouse-connect
We will use MyScaleDB (opens new window) as the vector database for this RAG application. MyScaleDB is a SQL vector database that uses familiar SQL syntax to efficiently retrieve relevant documents for the LLMs. It offers 5 million free vector storage, allowing us to utilize its capabilities without any cost.

# Making Your RAG Application
Once you've laid the foundation for your RAG application with Cohere and Hugging Face, it's time to put your creation to the test and refine its performance for optimal results.
# Load the Data
First, we need to load the data using the TextLoader from the langchain.document_loaders module. We will use Microsoft's WikiQA Corpus (opens new window) for this tutorial.
from langchain.document_loaders import TextLoader
loader = TextLoader('wikiQA-dev.txt', encoding='utf-8')
documents = loader.load()
text = documents[0].page_content
# Split the Text
Next, we split the loaded text into chunks using the CharacterTextSplitter. This helps in managing large documents by breaking them into smaller, manageable pieces. Splitting the text is necessary for processing large documents efficiently and allows for better handling and retrieval of specific sections.
from langchain_text_splitters import CharacterTextSplitter
# Split the text into chunks
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=400,
chunk_overlap=100,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([text])
# Load the Pre-trained Model and Tokenizer
We use the sentence-transformers/all-MiniLM-L6-v2 model from Hugging Face to generate text embeddings. The tokenizer and model are loaded, and a function is defined to get text embeddings. Embeddings are numerical representations of text that capture its semantic meaning, which is essential for similarity searches and comparisons.
from transformers import AutoTokenizer, AutoModel
import torch
# Load the pre-trained tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
# Function to get text embeddings
def get_text_embeddings(text):
inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True)
with torch.no_grad():
embeddings = model(inputs).last_hidden_state.mean(dim=1)
return embeddings.numpy().flatten()
# Generate Embeddings for Text Chunks
For each chunk of text, we generate embeddings and store them in a DataFrame along with the original text. This step helps us to manage the data more effectively, leading to ease during storage.
import pandas as pd
# Generate embeddings for each text chunk
page_contents = []
embeddings_list = []
for segment in texts:
embeddings_list.append(get_text_embeddings(segment.page_content))
page_contents.append(segment.page_content)
df = pd.DataFrame({
'page_content': page_contents,
'embeddings': embeddings_list
})
# Connect to MyScaleDB
We connect to the MyScaleDB (opens new window) database to store the embeddings and text chunks. Follow the steps to get credentials of your MyScaleDB cluster (opens new window).
import clickhouse_connect
# Connect to ClickHouse
client = clickhouse_connect.get_client(
host='your_host',
port=443,
username='your_user_name',
password='your_password'
)
# Create and Populate MyScaleDB Table
We create a table in MyScale to store the text chunks and embeddings, then insert the data into the table. This step structures the data within the database, making it ready for efficient querying and retrieval.
# Create the table
client.command("""
CREATE TABLE IF NOT EXISTS default.QnA (
id Int64,
page_content String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 384
) ENGINE = MergeTree() ORDER BY id
""")
# Insert data into the table
batch_size = 100
num_batches = (len(df) + batch_size - 1) // batch_size
for i in range(num_batches):
batch_data = df[i * batch_size: (i + 1) * batch_size]
client.insert('default.QnA', batch_data.values.tolist(), column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches} inserted.")
# Add Vector Index to the Table
We add a vector index to the table to facilitate efficient similarity searches. The vector index enhances the retrieval process by enabling fast lookups of embeddings, which is crucial for finding similar documents based on their semantic content.
# Add vector index to the table
client.command("""
ALTER TABLE default.QnA
ADD VECTOR INDEX vector_index embeddings
TYPE MSTG
""")
# Retrieve Relevant Documents
We define a function to retrieve the most relevant documents based on a user's query. The function calculates the distance between the query embeddings and the stored embeddings to find the most relevant documents.
# Function to retrieve relevant documents
def get_relevant_docs(user_query, top_k):
query_embeddings = get_text_embeddings(user_query).tolist()
results = client.query(f"""
SELECT page_content,
distance(embeddings, {query_embeddings}) as dist FROM default.QnA ORDER BY dist LIMIT {top_k}
""")
relevant_docs = []
doc_counter = 1
for row in results.named_results():
doc_key = f"doc{doc_counter}"
relevant_docs.append({doc_key: row['page_content']})
doc_counter += 1
return relevant_docs
# Example query
query = "How are epithelial tissues joined together?"
relevant_docs = get_relevant_docs(query, 8)
print(relevant_docs)
# Use Cohere for Enhanced Responses
We use Cohere's API to enhance the responses by querying the retrieved documents. Cohere's language model processes the query and the retrieved documents to generate a more comprehensive and accurate response. This step integrates the power of advanced language models with our retrieval system.
import cohere
# Connect to Cohere
co = cohere.Client('your-cohere-client-api')
# Query the relevant documents using Cohere
response = co.chat(
model='command-r-plus',
message="How are epithelial tissues joined together?",
documents=relevant_docs
)
print(response.text)
# Wrapping Up and Next Steps
As we conclude our journey of exploring RAG Applications with Cohere and Hugging Face, it's essential to reflect on the challenges encountered and the growth experienced throughout this process.
Embarking on the development of a RAG pipeline (opens new window) can present unexpected hurdles, leading to questions about performance disparities. However, by leveraging tools like Cohere's Command-R Model and Hugging Face's Pre-trained Models, developers can navigate these challenges effectively. The integration of retrieval and generation methods demands meticulous fine-tuning to achieve optimal results, a task that requires perseverance and strategic adjustments.
Another important component that directly affects the performance of any RAG systems is the vector database, which determines how quickly your data can be retrieved and how swiftly users receive responses. So the choice of the right vector database is extremely important when designing a RAG system.
However, many databases become slower during scaling. MyScaleDB (opens new window) is an open-source SQL vector database built on ClickHouse. Its high scalability inherited from ClickHouse effortlessly manages large-scale data, providing users with a powerful and flexible data management solution to build scalable RAG systems. Besides, it has shown better performance (opens new window) than most of its competitors in terms of speed and accuracy.
Delving deeper into advanced features offered by Cohere and Hugging Face, developers can unlock new dimensions of efficiency and performance in their RAG Applications. From optimizing retrieval mechanisms to customizing generation processes, these platforms provide a wealth of tools for enhancing application capabilities further.



