
In the realm of AI advancements, RAG applications stand out as transformative tools reshaping diverse sectors. These applications offer immense value to businesses by enhancing data analysis capabilities and predictive functions. Leveraging a combination of retrieval and generation models, RAG applications streamline information retrieval (opens new window) processes, enabling researchers to swiftly access a wealth of knowledge across various domains.
Companies spanning industries are increasingly turning to RAG to elevate their AI potential. The fusion of retrieval and generation components in RAG applications facilitates the analysis of extensive customer data, deriving actionable insights that drive personalized recommendations. This synergy empowers enterprises to harness the power of generative AI (opens new window) technology confidently for a wide array of applications.Moreover, the architecture of RAG applications combines information retrieval with text generation (opens new window) models, granting access to databases for responding effectively to user queries.
By fine-tuning large language models through techniques like embedding quantization (opens new window) and Retrieval Augmented Fine Tuning (RAFT), developers enhance the robustness and efficiency (opens new window) of RAG applications.
# How Claude Enhances RAG Models
Claude 3 (opens new window), developed by Anthropic, is an advanced AI model family that sets new standards in accuracy and context handling. The Claude 3 family includes three models: Haiku, Sonnet, and Opus, each designed for different needs. These models are known for their high factual accuracy and ability to maintain context over long conversations. Notably, the Opus model outperforms GPT-4 in several benchmarks, including graduate-level reasoning and basic math tests. With a context window of up to 200,000 tokens, (opens new window) Claude 3 can handle extensive text inputs more effectively than its competitors.
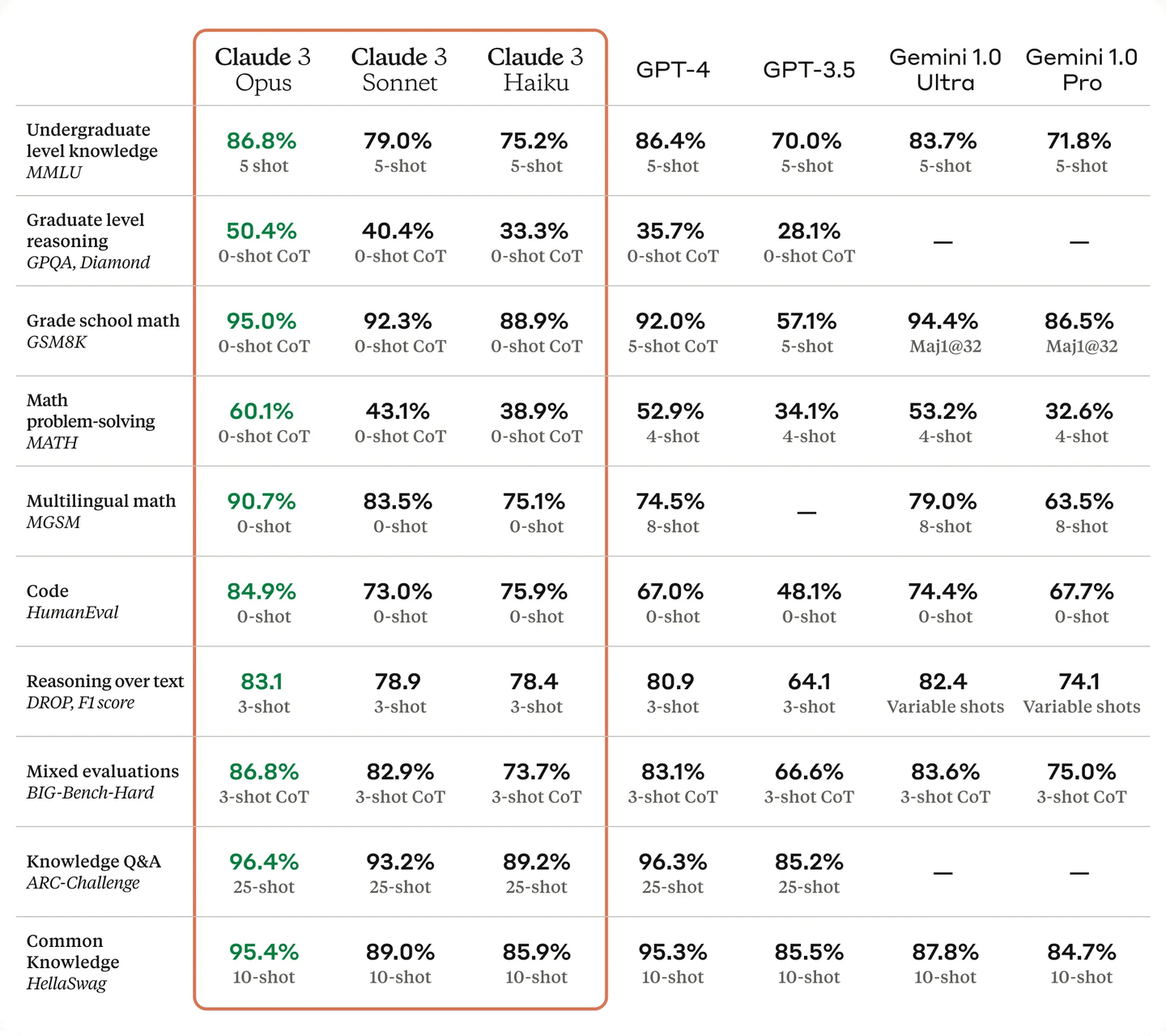
In addition to their performance, Claude 3 models prioritize ethical AI use and safety. They are designed to reduce biases, protect user privacy, and provide accurate responses even to complex prompts. These models also support both text and visual inputs, making them versatile for various applications such as content creation and data analysis. With strong partnerships and accessibility through various platforms, Claude 3 models are well-positioned to drive innovation and efficiency in multiple fields.
# Why Choose Hugging Face for RAG Models
Hugging Face (opens new window) is a leading platform known for its extensive library of pre-trained models (opens new window), which are optimized for various natural language processing tasks, including Retrieval-Augmented Generation (RAG) (opens new window). These models span dense retrieval, sequence-to-sequence generation, and other advanced tasks, making it easy for developers to set up and experiment with different RAG configurations. The platform's user-friendly APIs and comprehensive documentation further simplify the integration and fine-tuning process, allowing even those new to RAG models to implement effective systems quickly. Leveraging Hugging Face's tools, such as LangChain and Ray, developers can build scalable and high-performance RAG systems that efficiently handle large-scale data and complex queries.
In this blog, we will specifically focus on using Hugging Face's embedding models. Hugging Face offers a variety of embedding models that are crucial for the initial step of RAG systems: retrieving relevant documents. These models are designed to produce high-quality embeddings, which are essential for accurate and efficient information retrieval. By using Hugging Face's embedding models, we can ensure that our RAG system retrieves the most relevant context for any given query, thereby improving the overall accuracy and performance of the generated responses. This choice allows us to leverage the robustness and versatility of Hugging Face's offerings while tailoring our implementation to the specific needs of embedding generation.
# Building a RAG Application with Claude 3 and Hugging Face Embeddings
Now, let’s build a RAG application using Claude 3 and Hugging Face embedding models. We will go through the steps of setting up the environment, loading documents, creating embeddings, and using the Claude 3 model to generate answers from the retrieved documents.
# Setting Up the Environment
First, we need to install the necessary libraries. Uncomment the following line and run it to install the required packages. If the libraries are installed on your system, you can skip this step.
pip install langchain sentence-transformers anthropic
This will install langchain, sentence-transformers, and anthropic libraries needed for our RAG system.
# Setting Up Environment Variables
Next, we need to set up the environment variables for MyScale and Claude 3 API connections. We will use MyScaleDB (opens new window) as a vector database for this RAG application because it offers high performance, scalability, and efficient data retrieval capabilities.
import os
# Setting up the vector database connections
os.environ["MYSCALE_HOST"] = "your-host-name"
os.environ["MYSCALE_PORT"] = "443"
os.environ["MYSCALE_USERNAME"] = "your-user-name"
os.environ["MYSCALE_PASSWORD"] = "your-password-here"
# Setting up the API key for the Claude 3
os.environ["ANTHROPIC_API_KEY"] = "your-claude-api-key-here"
This script sets up the necessary environment variables for connecting to the MyScale vector database and the Claude 3 API.
Note:
If you don't have a MyScaleDB account, you can visit the MyScale website (opens new window) to sign up for a free account and follow the QuickStart (opens new window) guide. For using the Claude 3 API, you need to create an account on the Claude Console (opens new window).
# Importing Necessary Libraries
We then import the required libraries for document loading, splitting, embedding, and interacting with the Claude 3 model.
# To split the documents into chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# To use MyScale as a vector database
from langchain_community.vectorstores import MyScale
# To use Hugging Face for embeddings
from langchain_huggingface import HuggingFaceEmbeddings
# To load a wikipedia page
from langchain_community.document_loaders.wikipedia import WikipediaLoader
import anthropic
These libraries will help us manage documents, create embeddings, and interact with the Claude 3 model.
# Initializing the Claude 3 Client
Initialize the client for the Claude 3 API to communicate with the model.
client = anthropic.Anthropic()
# Loading Documents
For this example, we will load documents from Wikipedia using the WikipediaLoader.
loader = WikipediaLoader(query="Fifa")
# Load the documents
docs = loader.load()
This loads documents related to "Fifa" from Wikipedia.
# Splitting Documents
We split the loaded documents into manageable chunks using RecursiveCharacterTextSplitter.
character_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
docs = character_splitter.split_documents(docs)
This ensures that the documents are split into chunks of 1000 characters with an overlap of 200 characters.
# Creating Embeddings
Next, we use a Hugging Face embedding model to create embeddings for our document chunks.
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-base-en-v1.5")
docsearch = MyScale(embedding_function=embeddings.embed_documents)
docsearch.add_documents(docs)
This step generates embeddings for the document chunks and adds them to our MyScale vector store.
# Testing Document Search
We test the document search functionality to ensure that our embeddings and vector store are working correctly.
query = "Who won fifa Fifa 2022?"
docs = docsearch.similarity_search(query, 3)
docs
This performs a similarity search on the query "Who won Fifa 2022?" and retrieves the top 3 most relevant documents. It will return documents like this:
[Document(page_content="The FIFA World Cup, often called the World Cup, is an international association football competition among the senior men's national teams of the members of the Fédération Internationale de Football Association (FIFA), the sport's global governing body. The tournament has been held every four years since the inaugural tournament in 1930, with the exception of 1942 and 1946 due to the Second World War. The reigning champions are Argentina, who won their third title at the 2022 tournament.\\nThe contest starts with the qualification phase, which takes place over the preceding three years to determine which teams qualify for the tournament phase. In the tournament phase, 32 teams compete for the title at venues within the host nation(s) over the course of about a month. The host nation(s) automatically qualify for the group stage of the tournament. The competition is scheduled to expand to 48 teams, starting with the 2026 tournament.", metadata={'source': '<https://en.wikipedia.org/wiki/FIFA_World_Cup>', 'summary': "The FIFA World Cup, often called the World Cup, is an international association football competition among the senior men's national teams of the members of the Fédération Internationale de Football Association (FIFA), the sport's global governing body. The tournament has been held every four years since the inaugural tournament in 1930, with the exception of 1942 and 1946 due to the Second World War. The reigning champions are Argentina, who won their third title at the 2022 tournament.\\nThe contest starts with the qualification phase, which takes place over the preceding three years to determine which teams qualify for the tournament phase. In the tournament phase, 32 teams compete for the title at venues within the host nation(s) over the course of about a month. The host nation(s) automatically qualify for the group stage of the tournament. The competition is scheduled to expand to 48 teams, starting with the 2026 tournament.\\nAs of the 2022 FIFA World Cup, 22 final tournaments have been held since the event's inception in 1930, and a total of 80 national teams have competed. The trophy has been won by eight national teams. With five wins, Brazil is the only team to have played in every tournament. The other World Cup winners are Germany and Italy, with four titles each; Argentina, with three titles; France and inaugural winner Uruguay, each with two titles; and England and Spain, with one title each.\\nThe World Cup is the most prestigious association football tournament in the world, as well as the most widely viewed and followed single sporting event in the world. The viewership of the 2018 World Cup was estimated to be 3.57 billion, close to half of the global population, while the engagement with the 2022 World Cup was estimated to be 5 billion, with about 1.5 billion people watching the final match.\\nSeventeen countries have hosted the World Cup, most recently Qatar, who hosted the 2022 event. The 2026 tournament will be jointly hosted by Canada, the United States and Mexico, which will give Mexico the distinction of being the first country to host games in three World Cups.\\n\\n", 'title': 'FIFA World Cup'}),
Document(page_content="The 2026 FIFA World Cup, marketed as FIFA World Cup 26, will be the 23rd FIFA World Cup, the quadrennial international men's soccer championship contested by the national teams of the member associations of FIFA. The tournament will take place from June 11 to July 19, 2026. It will be jointly hosted by 16 cities in three North American countries: Canada, Mexico, and the United States. The tournament will be the first hosted by three nations and the first North American World Cup since 1994. Argentina is the defending champion.", metadata={'source': '<https://en.wikipedia.org/wiki/2026_FIFA_World_Cup>', 'summary': "The 2026 FIFA World Cup, marketed as FIFA World Cup 26, will be the 23rd FIFA World Cup, the quadrennial international men's soccer championship contested by the national teams of the member associations of FIFA. The tournament will take place from June 11 to July 19, 2026. It will be jointly hosted by 16 cities in three North American countries: Canada, Mexico, and the United States. The tournament will be the first hosted by three nations and the first North American World Cup since 1994. Argentina is the defending champion.\\nThis tournament will be the first to include 48 teams, expanded from 32. The United 2026 bid beat a rival bid by Morocco during a final vote at the 68th FIFA Congress in Moscow. It will be the first World Cup since 2002 to be hosted by more than one nation. With its past hosting of the 1970 and 1986 tournaments, Mexico will become the first country to host or co-host the men's World Cup three times. The United States last hosted the men's World Cup in 1994, whereas it will be Canada's first time hosting or co-hosting the men's tournament. The event will also return to its traditional northern summer schedule after the 2022 edition in Qatar was held in November and December.", 'title': '2026 FIFA World Cup'}),
Document(page_content="The 2022 FIFA World Cup was the 22nd FIFA World Cup, the world championship for national football teams organized by FIFA. It took place in Qatar from 20 November to 18 December 2022, after the country was awarded the hosting rights in 2010. It was the first World Cup to be held in the Arab world and Muslim world, and the second held entirely in Asia after the 2002 tournament in South Korea and Japan.\\nThis tournament was the last with 32 participating teams, with the number of teams being increased to 48 for the 2026 edition. To avoid the extremes of Qatar's hot climate, the event was held in November and December instead of during the traditional months of May, June, or July. It was held over a reduced time frame of 29 days with 64 matches played in eight venues across five cities. Qatar entered the event—their first World Cup—automatically as the host's national team, alongside 31 teams determined by the qualification process.", metadata={'source': '<https://en.wikipedia.org/wiki/2022_FIFA_World_Cup>', 'summary': "The 2022 FIFA World Cup was the 22nd FIFA World Cup, the world championship for national football teams organized by FIFA. It took place in Qatar from 20 November to 18 December 2022, after the country was awarded the hosting rights in 2010. It was the first World Cup to be held in the Arab world and Muslim world, and the second held entirely in Asia after the 2002 tournament in South Korea and Japan.\\nThis tournament was the last with 32 participating teams, with the number of teams being increased to 48 for the 2026 edition. To avoid the extremes of Qatar's hot climate, the event was held in November and December instead of during the traditional months of May, June, or July. It was held over a reduced time frame of 29 days with 64 matches played in eight venues across five cities. Qatar entered the event—their first World Cup—automatically as the host's national team, alongside 31 teams determined by the qualification process.\\nArgentina were crowned the champions after winning the final against the title holder France 4–2 on penalties following a 3–3 draw after extra time. It was Argentina's third title and their first since 1986, as well as being the first nation from outside of Europe to win the tournament since 2002. French player Kylian Mbappé became the first player to score a hat-trick in a World Cup final since Geoff Hurst in the 1966 final and won the Golden Boot as he scored the most goals (eight) during the tournament. Mbappé also became the first player to score in two consecutive finals since Vavá of Brazil did the same in 1958 and 1962. Argentine captain Lionel Messi was voted the tournament's best player, winning the Golden Ball. The tournament has been considered exceptionally poetic as the capstone of his career, for some commentators fulfilling a previously unmet criterion to be regarded as one of the greatest players of all time. Teammates Emiliano Martínez and Enzo Fernández won the Golden Glove, awarded to the tournament's best goalkeeper; and the Young Player Award, awarded to the tournament's best young player, respectively. With 172 goals, the tournament set a record for the highest number of goals scored in the 32-team format, with every participating team scoring at least one goal. Morocco became the first African nation to top Group stages with 7 points.\\nThe choice to host the World Cup in Qatar attracted significant criticism, with concerns raised over the country's treatment of migrant workers, women, and members of the LGBT community, as well as Qatar's climate, lack of a strong football culture, scheduling changes, and allegations of bribery for hosting rights and wider FIFA corruption.", 'title': '2022 FIFA World Cup'})]
Now, the next step is to use the Claude 3 model to get the required result from the retrieved context.
# Preparing the Query Context
We prepare the context from the retrieved documents for the Claude 3 model.
stre = "".join(doc.page_content for doc in docs)
This concatenates the content of the retrieved documents into a single string.
# Setting the Model
Specify the model we want to use for generating answers.
model = 'claude-3-opus-20240229'
# Generating the Answer
Finally, we use the Claude 3 model to generate an answer based on the provided context.
response = client.messages.create(
system = "You are a helpful research assistant. You will be shown data from a vast knowledge base. You have to answer the query from the provided context.",
messages=[
{"role": "user", "content": "Context: " + stre + "\\\\n\\\\n Query: " + query},
],
model= model,
temperature=0,
max_tokens=160
)
response.content[0].text
This script sends the context and query to the Claude 3 model and retrieves the generated response. You’ll get an output like this:
'According to the provided context, Argentina won the 2022 FIFA World Cup, making them the
reigning champions. The passage states:\\n\\n"The reigning champions are Argentina, who won their third title at the 2022 tournament."'
By following these steps, we have built a RAG application that uses Hugging Face embeddings and the Claude 3 model to retrieve and generate answers from a knowledge base.
# Why Choose MyScaleDB for RAG models
MyScaleDB stands out as an optimal choice for RAG applications due to its combination of advanced vector search capabilities and SQL support. Built on top of ClickHouse, it allows seamless integration of vector and structured data, enabling complex and efficient queries. This integration simplifies data management and improves the performance and accuracy of the RAG system, making it easier to handle large volumes of data efficiently.
Another significant advantage of MyScaleDB is its cost efficiency and scalability. It is designed to be one of the most affordable vector databases on the market while delivering superior performance compared to its competitors. It offers advanced vector indexing techniques like Multi-Scale Tree Graph (MSTG), which reduces resource consumption and enhances precision. Features like dynamic batching and multi-threading support high volumes of simultaneous requests, maintaining low latency and high throughput. These capabilities make MyScaleDB a reliable and efficient database solution for scalable RAG applications

# Conclusion
Developing simple RAG applications are relatively straightforward, but optimizing them and maintaining the accuracy of their responses is challenging. This is why the right choice of tools, such as LLMs, vector databases, and embedding models, is crucial. Each component plays a vital role in ensuring the application runs efficiently and provides accurate and relevant responses.
The choice of vector databases is particularly important because it provides the necessary context for the LLM. MyScaleDB (opens new window) has proven to outperform leading vector databases (opens new window) in terms of performance and accuracy. Additionally, MyScaleDB offers new users 5 million free vector storage, allowing them to test its functionalities and see its benefits firsthand. This makes it an excellent choice for those looking to build high-performing RAG systems.



