
Basic Retrieval-Augmented Generation (RAG) (opens new window) data pipelines often rely on hard-coded steps, following a predefined path every time they run. In these systems, there is no real-time decision-making, and they do not dynamically adjust actions based on input data. This limitation can reduce flexibility and responsiveness in complex or changing environments, highlighting a major weakness in traditional RAG systems.
LlamaIndex resolves this limitation by introducing agents (opens new window). Agents are a step beyond our query engines in that they can not only "read" from a static source of data, but can dynamically ingest and modify data from various tools. Powered by an LLM, these agents are designed to perform a series of actions to accomplish a specified task by choosing the most suitable tools from a provided set. These tools can be as simple as basic functions or as complex as comprehensive LlamaIndex query engines. They process user inputs or queries, make internal decisions on how to handle these inputs, and decide whether additional steps are necessary or if a final result can be delivered. This ability to perform automated reasoning and decision-making makes agents highly adaptable and efficient for complex data processing tasks.
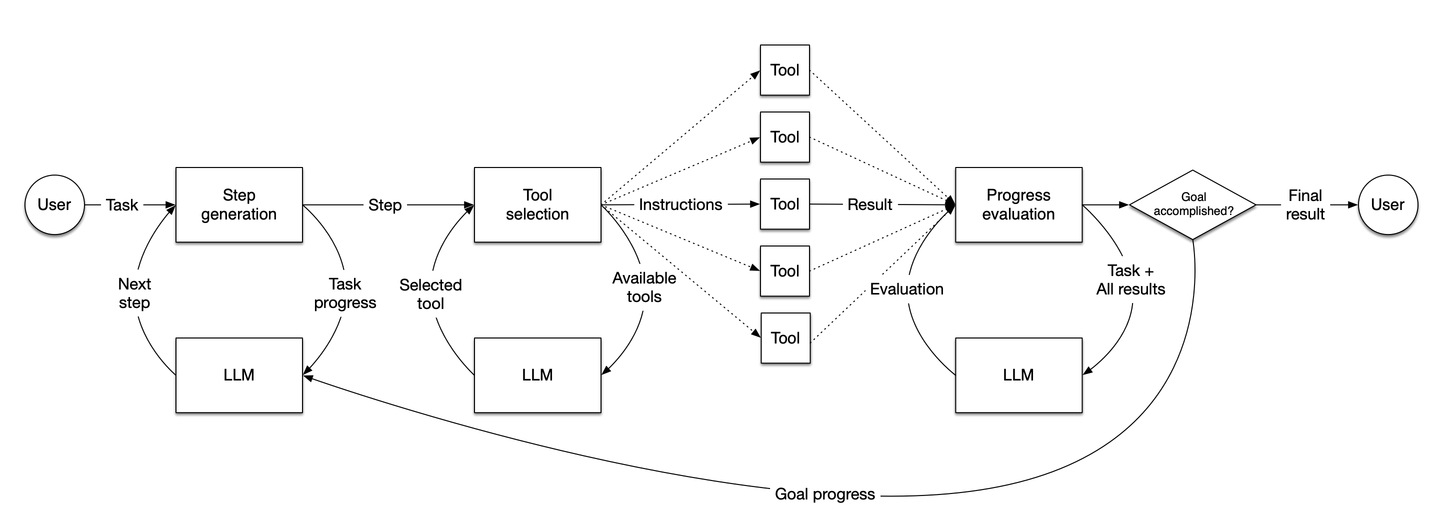
Source: LlamaIndex
The diagram illustrates the workflow of LlamaIndex agents. How they generate steps, make decisions, select tools, and evaluate progress to dynamically accomplish tasks based on user inputs.
# Core Components of a LlamaIndex Agent
There are two main components of an agent in LlamaIndex: AgentRunner and AgentWorker.
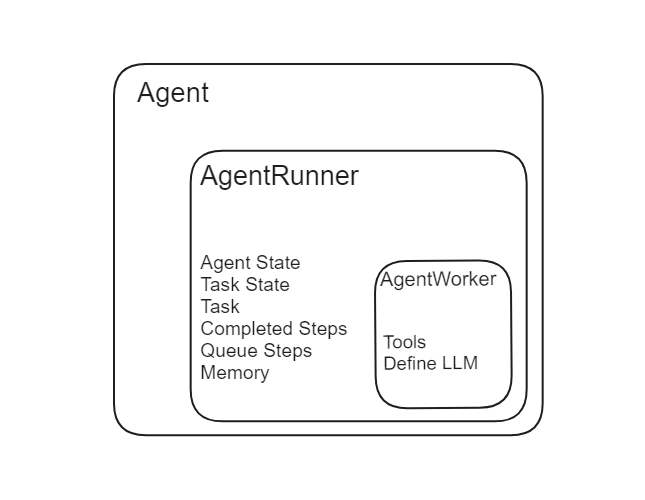
Source: LlamaIndex
# Agent Runner
The Agent Runner is the orchestrator within LlamaIndex. It manages the state of the agent, including conversational memory, and provides a high-level interface for user interaction. It creates and maintains tasks and is responsible for running steps through each task. Here’s a detailed breakdown of its functionalities:
- Task Creation: The Agent Runner creates tasks based on user queries or inputs.
- State Management: It stores and maintains the state of the conversation and tasks.
- Memory Management: It manages conversational memory internally, ensuring context is maintained across interactions.
- Task Execution: It runs steps through each task, coordinating with the Agent Worker.
Unlike LangChain agents (opens new window), which require developers to manually define and pass memory, LlamaIndex agents handle memory management internally.
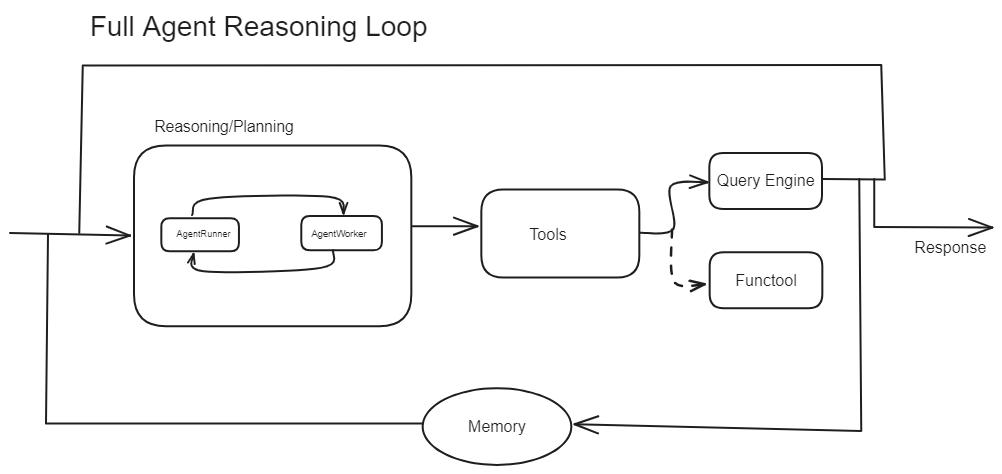
Source: LlamaIndex
# Agent Worker
The Agent Worker controls the step-wise execution of a task given by the Agent Runner. It is responsible for generating the next step in a task based on the current input. Agent Workers can be customized to include specific reasoning logic, making them highly adaptable to different tasks. Key aspects include:
- Step Generation: Determines the next step in the task based on current data.
- Customization: This can be tailored to handle specific types of reasoning or data processing.
The Agent Runner manages task creation and state, while the Agent Worker carries out the steps of each task, acting as the operational unit under the Agent Runner’s direction.
# Types of Agents in LlamaIndex
LlamIndex offers different kinds of agents designed for specific tasks and functions.
# Data Agents
Data Agents (opens new window) are specialized agents designed to handle a variety of data tasks, including retrieval and manipulation. They can operate in both read and write modes and interact seamlessly with different data sources.
Data Agents can search, retrieve, update, and manipulate data across various databases and APIs. They support interaction with platforms like Slack, Shopify, Google, and more, allowing for easy integration with these services. Data Agents can handle complex data operations such as querying databases, calling APIs, updating records, and performing data transformations. Their adaptable design makes them suitable for a wide range of applications, from simple data retrieval to intricate data processing pipelines.
from llama_index.agent import OpenAIAgent, ReActAgent
from llama_index.llms import OpenAI
# import and define tools
...
# initialize llm
llm = OpenAI(model="gpt-3.5-turbo")
# initialize openai agent
agent = OpenAIAgent.from_tools(tools, llm=llm, verbose=True)
# initialize ReAct agent
agent = ReActAgent.from_tools(tools, llm=llm, verbose=True)
# use agent
response = agent.chat("What is (121 * 3) + 42?")
# Custom Agents
Custom Agents give you a lot of flexibility and customization options. By subclassing CustomSimpleAgentWorker, you can define specific logic and behavior for your agents. This includes handling complex queries, integrating multiple tools, and implementing error-handling mechanisms.
You can tailor Custom Agents to meet specific needs by defining step-by-step logic, retry mechanisms, and integrating various tools. This customization lets you create agents that manage sophisticated tasks and workflows, making them highly adaptable to different scenarios. Whether managing intricate data operations or integrating with unique services, Custom Agents provide the tools you need to build specialized, efficient solutions.
# Tools and Tool Specs
Tools (opens new window) are the most important component of any agent. They allow the agent to perform various tasks and extend its functionality. By using different types of tools, an agent can execute specific operations as needed. This makes the agent highly adaptable and efficient.
# Function Tools
Function Tools lets you convert any Python function into a tool that an agent can use. This feature is useful for creating custom operations, enhancing the agent's ability to perform a wide range of tasks.
You can transform simple functions into tools that the agent incorporates into its workflow. This can include mathematical operations, data processing functions, and other custom logic.
You can convert your Python function into a tool like this:
from llama_index.core.tools import FunctionTool
def multiply(a: int, b: int) -> int:
"""Multiple two integers and returns the result integer"""
return a * b
multiply_tool = FunctionTool.from_defaults(fn=multiply)
The FunctionTool method in LlamaIndex allows you to convert any Python function into a tool that an agent can use. The name of the function becomes the name of the tool, and the function's docstring serves as the tool's description.
# QueryEngine Tools
QueryEngine Tools wrap existing query engines, allowing agents to perform complex queries over data sources. These tools integrate with various databases and APIs, enabling the agent to retrieve and manipulate data efficiently.
These tools enable agents to interact with specific data sources, execute complex queries, and retrieve relevant information. This integration allows the agent to use the data effectively in its decision-making processes.
To convert any query engine to a query engine tool, you can use the following code:
from llama_index.core.tools import QueryEngineTool
from llama_index.core.tools import ToolMetadata
query_engine_tools = QueryEngineTool(
query_engine="your_index_as_query_engine_here",
metadata=ToolMetadata(
name="name_your_tool",
description="Provide the description",
),
)
The QueryEngineTool method allows you to convert a query engine into a tool that an agent can use. The ToolMetadata class helps define the name and description of this tool. The name of the tool is set by the name attribute, and the description is set by the description attribute.
Note: The description of the tool is extremely important because it helps the LLM decide when to use that tool.

# Building an AI Agent Using MyScaleDB and LlamaIndex
Let's build an AI agent (opens new window) using both a Query Engine Tool and a Function Tool to demonstrate how these tools can be integrated and utilized effectively.
# Install the Necessary Libraries
First, install the required libraries by running the following command in your terminal:
pip install myscale-client llama-index
We will use MyScaleDB (opens new window) as a vector search engine to develop the query engine. It's an advanced SQL vector database that has been specially designed for scalable applications.
# Get the Data for the Query Engine
We will use the Nike catalog dataset (opens new window) for this example. Download and prepare the data using the following code:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
import requests
url = 'https://niketeam-asset-download.nike.net/catalogs/2024/2024_Nike%20Kids_02_09_24.pdf?cb=09302022'
response = requests.get(url)
with open('Nike_Catalog.pdf', 'wb') as f:
f.write(response.content)
reader = SimpleDirectoryReader(input_files=["Nike_Catalog.pdf"])
documents = reader.load_data()
This code will download the Nike catalog PDF and load the data for use in the query engine.
# Connecting with MyScaleDB
Before using MyScaleDB, we need to establish a connection:
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your_host_here',
port=443,
username='your_username_here',
password='your_password_here'
)
To learn how to get the cluster details and read more about MyScale, you can refer to the MyScaleDB quickstart (opens new window) guide.
# Create the Query Engine tool
Let’s first build the first tool for our agent, which is the query engine tool. For that, let’s first develop the query engine using MyScaleDB and add the Nike catalog data to the vector store.
from llama_index.vector_stores.myscale import MyScaleVectorStore
from llama_index.core import StorageContext
vector_store = MyScaleVectorStore(myscale_client=client)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)
query_engine = index.as_query_engine()
Once the data is ingested into the vector store and an index is created. The next step is to transform the Query Engine into a tool. For that, we will use the QueryEngineTool method of the LlamaIndex.
from llama_index.core.tools import QueryEngineTool
from llama_index.core.tools import ToolMetadata
query_engine_tool = QueryEngineTool(
query_engine=index,
metadata=ToolMetadata(
name="nike_data",
description="Provide information about the Nike products. Use a detailed plain text question as input to the tool."
),
)
The QueryEngineTool takes query_engine and meta_data as arguments. In the metadata, we define the name of the tool with the description.
# Create the Function Tool
Our next tool is a simple Python function that multiplies two numbers. This method will be transformed into a tool using the FunctionTool of the LlamaIndex.
from llama_index.core.tools import FunctionTool
# Define a simple Python function
def multiply(a: int, b: int) -> int:
"""Multiply two integers and return the result."""
return a * b
# Change function to a tool
multiply_tool = FunctionTool.from_defaults(fn=multiply)
After this, we are done with the tools. The LlamaIndex agents takes tools as a python list. So, let’s add the tools to a list.
tools = [multiply_tool, query_engine_tool]
# Define the LLM
Let’s define the LLM, the heart of any LlamaIndex agent. The choice of LLM is crucial because the better the understanding and performance of the LLM, the more effectively it can act as a decision-maker and handle complex problems. We will use gpt-3.5-turbo model from OpenAI.
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-3.5-turbo")
# Initialize the Agent
As we saw earlier, an agent consists of an Agent Runner and Agent Worker. These are two building blocks of an agent. Now, we will explore how they work in practice. We have implemented the code below in two ways:
- Custom Agent: The first method is to initialize the Agent worker first with the tools and llm. Then, pass the Agent worker to the Agent Runner to handle the complete agent. Here, you import the necessary modules and compose your own agent.
from llama_index.core.agent import AgentRunner
from llama_index.agent.openai import OpenAIAgentWorker
# Method 2: Initialize AgentRunner with OpenAIAgentWorker
openai_step_engine = OpenAIAgentWorker.from_tools(tools, llm=llm, verbose=True)
agent1 = AgentRunner(openai_step_engine)
- Use Predefined Agent: The second method is to use the Agents which are the subclass of
AgentRunnerthat bundles theOpenAIAgentWorkerunder the hood. Therefore, we do not need to define the AgentRunner or AgentWorkers ourselves, as they are implemented on the backend.
from llama_index.agent.openai import OpenAIAgent
# Initialize OpenAIAgent
agent = OpenAIAgent.from_tools(tools, llm=llm, verbose=True)
Note: When verbose=true is set in LLMs, we gain insight into the model's thought process, allowing us to understand how it arrives at its answers by providing detailed explanations and reasoning.
Regardless of the initialization method, you can test the agents using the same method. Let’s test the first one:
# Call the custom agent
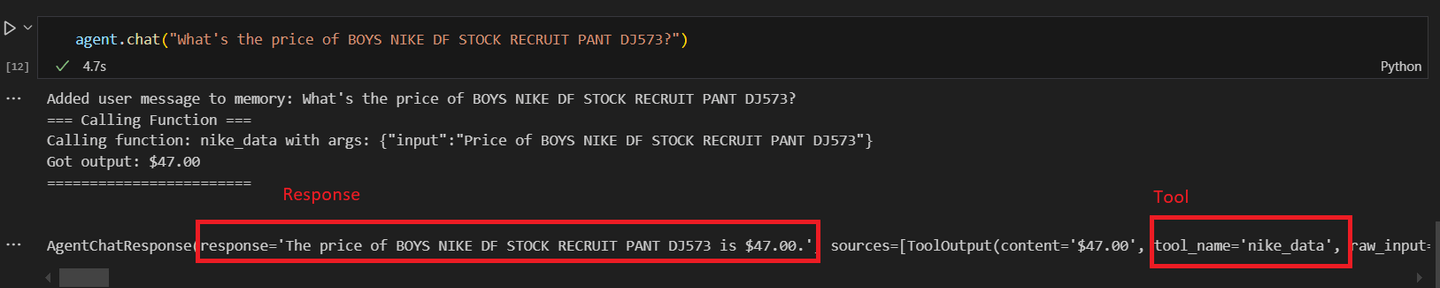
agent = agent.chat("What's the price of BOYS NIKE DF STOCK RECRUIT PANT DJ573?")
You should get a result similar to this:
Now, let’s call the first custom agent with the math operation.
# Call the second agent
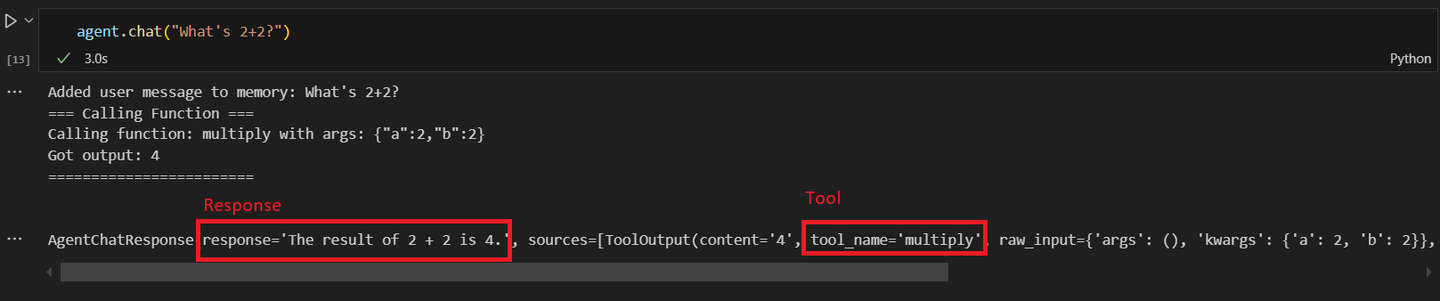
response = agent1.chat("What's 2+2?")
Upon calling the second agent, and asking for a math operation. You will get a response similar to this:
The potential for AI agents to handle complex tasks autonomously is expanding, making them invaluable in business settings where they can manage routine tasks and free up human workers for higher-value activities. As we move forward, the adoption of AI agents is expected to grow, further revolutionizing how we interact with technology and optimize our workflows.
# Conclusion
LlamaIndex agents offer a smart way to manage and process data, going beyond traditional RAG systems. Unlike static data pipelines, these agents make real-time decisions, adjusting their actions based on incoming data. This automated reasoning makes them highly adaptable and efficient for complex tasks. They integrate various tools, from basic functions to advanced query engines, to intelligently process inputs and deliver optimized results.
MyScaleDB is a top-tier vector database, especially suited for large-scale AI applications. Its MSTG algorithm (opens new window) outperforms others in scalability and efficiency, making it ideal for high-demand environments. Designed to handle large datasets and complex queries (opens new window) swiftly, MyScaleDB ensures fast and accurate data retrieval. This makes it an essential tool for creating robust and scalable AI applications, offering seamless integration and superior performance compared to other vector databases.
If you are interested in discuss more about building AI agent with MyScaleDB, please follow us on X (Twitter (opens new window)) or join our Discord (opens new window) community. Let’s build the future of data and AI together!



