
In today's world, recommendation systems have become vitally important to enhance the user experience across various platforms, including e-commerce, streaming services, news feeds, social media, and personalized learning.
In the realm of recommendation systems, conventional approaches relied on analyzing user-item interactions and assessing item similarities. However, with the advancements in the field of Artificial Intelligence, the area of recommendation systems has evolved as well, enhancing precision and tailoring recommendations to individual preferences.
# Widely Adopted Content Recommendation Approaches
There are three types of filtering used for content recommendation systems. Some use collaborative filtering (opens new window), some use content-based filtering (opens new window), and some use a hybrid of those two methods. Let's discuss them in detail.
# Content-Based Filtering
Content-based filtering focuses on the characteristics of the items themselves. It recommends items similar to those a user has previously shown interest in.
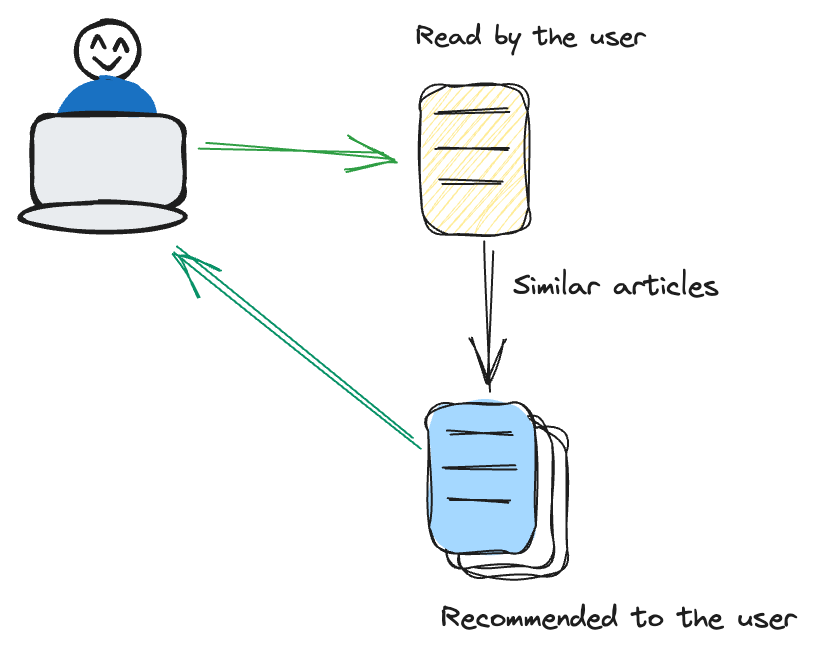
For example, if a user frequently watches thriller movies, the recommendation system adopts a tailored approach by suggesting additional films within the thriller genre. This method places a significant emphasis on the inherent characteristics of the items, such as genre, author, or artist. By honing in on these attributes, the system ensures a more targeted and content-specific recommendation strategy, aligning closely with the user's preferences.
# Collaborative Filtering
Collaborative filtering is user-centric. It analyzes patterns and similarities in user behavior to make recommendations.
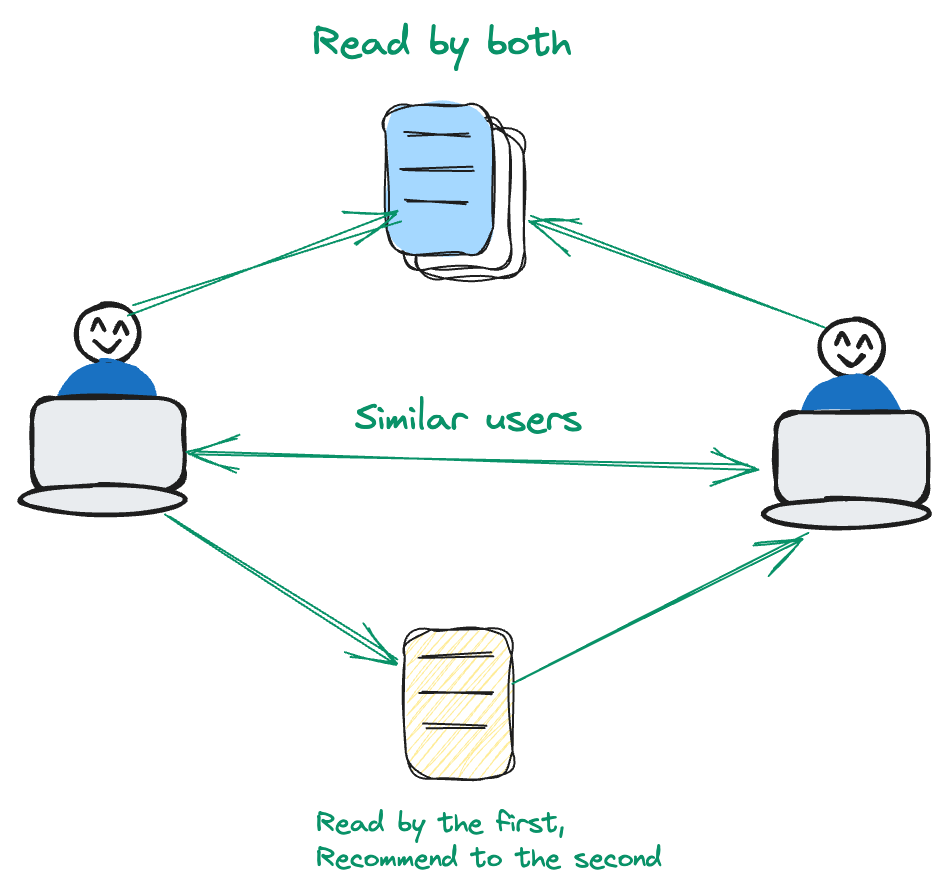
Consider a scenario where User A and User B share a common interest in a particular set of movies. Now, if User B expresses a liking for a movie that User A hasn't yet encountered, the recommendation system takes note. In this methodology, the emphasis lies on leveraging user interactions and preferences, diverging from a content-centric approach. By prioritizing the dynamic relationships between users and items, the system refines its recommendations for a more personalized user experience.
# Hybrid Techniques
Hybrid techniques ingeniously integrate the strengths of both Content-Based and Collaborative Filtering to enhance recommendation accuracy. By leveraging a dual approach that incorporates both item attributes and user preference patterns, this method adeptly tackles inherent limitations present when relying solely on each approach independently. Hybrid techniques are particularly effective in providing refined and diversified recommendations.
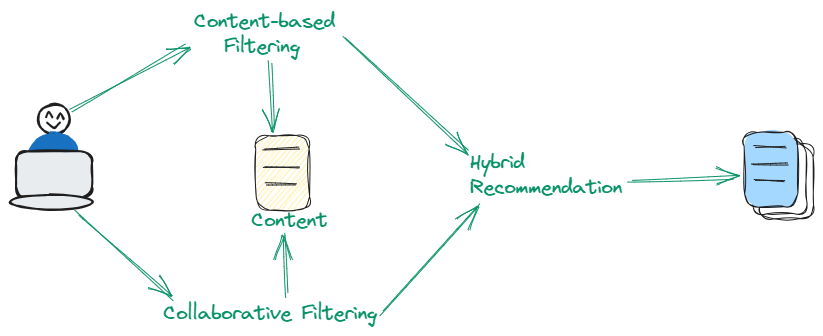
# Advanced Content Recommendation Approach
The rise of Large Language Models (LLMs) has significantly streamlined various tasks, notably the evolution of recommendation systems. For Modern recommendation systems, the conventional dependence on content or collaborative filtering has given way to a more sophisticated approach. Harnessing the power of semantics, modern recommendation systems navigate and explore linguistic meaning to propose related items.
In this blog, I will show you how to build a content recommendation system with this advanced approach. Let's first take a look at the tools required for this system.
![]()
# Tool and Technologies
We will use the OpenAI text embedding model (opens new window), MyScale as a vector database (opens new window), and TMDB 5000 Movie Dataset (opens new window) in this project.
- OpenAI: We will use OpenAIs model
text-embedding-3-smallto get the embeddings of the text and then use these embeddings to develop the model. - MyScale: MyScale is a SQL vector database that we use to store and process both structured and unstructured data in an optimized way.
- TMDB 5000 Movie Dataset: This dataset contains a collection of movie metadata, including cast, crew, budget, and revenue details.
# Loading the Data
We have two key CSV files: tmdb_5000_credits.csv and tmdb_5000_movies.csv. These files contain essential information about a diverse array of movies, which will form the basis of our recommendation system.
import pandas as pd
credits = pd.read_csv("tmdb_5000_credits.csv")
movies = pd.read_csv("tmdb_5000_movies.csv")
# Data Preprocessing
Data preprocessing is crucial for ensuring the quality of the recommendation system. We will merge the two CSV files and focus on the most relevant columns – title, overview, genres, cast, and crew. This step is about refining the data to make it suitable for our model.
credits.rename(columns = {'movie_id':'id'}, inplace = True)
df = credits.merge(movies, on = 'id')
df.dropna(subset = ['overview'], inplace=True)
df = df[['id', 'title_x', 'genres', 'overview', 'cast', 'crew']]
By merging and filtering our data, we've created a clean and focused dataset for the system.
# Generating the Corpus
Next, we generate a corpus for each movie by combining its overview, genre, cast, and crew into a single string. This comprehensive information helps the system in making accurate recommendations.
import pandas as pd
# Assuming 'df' is your DataFrame and it has the columns 'overview', 'genres', 'cast', and 'crew'
def generate_corpus(row):
overview, genre, cast, crew = row['overview'], row['genres'], row['cast'], row['crew']
corpus = ""
genre = ','.join([i['name'] for i in eval(genre)])
cast = ','.join([i['name'] for i in eval(cast)[:3]])
crew = ','.join(list(set([i['name'] for i in eval(crew) if i['job'] == 'Director' or i['job'] == 'Producer'])))
corpus += overview + " " + genre + " " + cast + " " + crew
return pd.Series([corpus, crew, cast, genre], index=['corpus', 'crew', 'cast', 'genres'])
# Apply the function to each row
df[['corpus', 'crew', 'cast', 'genres']] = df.apply(generate_corpus, axis=1)
# Getting the Embeddings
We then use OpenAI's embedding model text-embedding-3-small to convert our corpus into embeddings, which are numerical representations of the movie's content.
import os
import numpy as np
import openai
os.environ["OPENAI_API_KEY"] = "your-api-key"
def get_embeddings(text):
response = openai.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data
# Get the first 1000 entries because we can't pass the entire 5000 entries
#to embeddings model. If you want to get the embeddings of the entire dataset, you can apply a loop
df=df[0:1000]
embeddings=get_embeddings(df["corpus"].tolist())
vectors = [embedding.embedding for embedding in embeddings]
array = np.array(vectors)
embeddings_series = pd.Series(list(array))
df['embeddings'] = embeddings_series
By getting the vector representation of the text, we can now apply semantic search easily using MyScale.
# Setting up MyScale
As we have discussed at the start we will use the MyScale as a vector database for storing and managing data. Here, we will connect to MyScale in preparation for data storage.
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-host-name',
port=443,
username='your-user-name',
password='your-password'
)
Note: See Connection Details (opens new window) for more information on how to connect to the MyScale cluster
# Creating a Table
We now create a table according to our DataFrame. All the data will be stored in this table, including the embeddings.
client.command("""
CREATE TABLE default.movies (
id Int64,
title_x String,
genres String,
overview String,
cast String,
crew String,
corpus String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 1536
) ENGINE = MergeTree()
ORDER BY id
""")
The above SQL statements create a table named movies on the cluster. The CONSTRAINT make sure that all the vectors embedding are of the same length 1536.
# Storing the Data and Creating an Index in MyScale
In this step, we insert the processed data into MyScale. This involves batch-inserting the data to ensure efficient storage and retrieval.
batch_size = 100 # Adjust based on your needs
num_batches = len(df) // batch_size
for i in range(num_batches):
start_idx = i * batch_size
end_idx = start_idx + batch_size
batch_data = df[start_idx:end_idx]
client.insert("default.movies", batch_data.to_records(index=False).tolist(), column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches} inserted.")
client.command("""
ALTER TABLE default.movies
ADD VECTOR INDEX vector_index embeddings
TYPE MSTG
""")
# Generating Movie Recommendations
Finally, we create a function that generates movie recommendations based on user input. This function utilizes an exponential decay factor to give more relevance to recently watched movies, enhancing the recommendation quality.
import numpy as np
from IPython.display import clear_output
genres = []
for i in range(3):
genre = input("Enter a genre: ")
genres.append(genre)
genre_string = ', '.join(genres)
genre_embeddings=get_embeddings(genre_string)
embeddings=genre_embeddings[0].embedding
embeddings = np.array(genre_embeddings[0].embedding) # Convert to numpy array
decay_factor = 0.9 # Adjust as needed for exponential decay
while True:
clear_output(wait=True)
# Use the combined embeddings to query the database
results = client.query(f"""
SELECT title_x, genres,
distance(embeddings, {embeddings.tolist()}) as dist FROM default.movies ORDER BY dist LIMIT 10
""")
# Display the results
print("Recommended Movies:")
movies = []
for row in results.named_results():
print(row["title_x"])
movies.append(row['title_x'])
# Ask the user to select a movie
selection = int(input("Select a movie (or enter 0 to exit): "))
if selection == 0:
break
selected_movie = movies[selection - 1]
# Get the embeddings of the selected movie title
selected_movie_embeddings = get_embeddings(selected_movie)[0].embedding
selected_movie_embeddings_array = np.array(selected_movie_embeddings)
# Apply exponential decay and update combined_embeddings
embeddings = decay_factor * embeddings + (1 - decay_factor) * selected_movie_embeddings_array
# Normalize the combined embeddings
embeddings = embeddings / np.linalg.norm(embeddings)
we have now built a fully functional movie recommendation system using MyScale and vector embeddings. Feel free to experiment with this tutorial, or create your own according to the needs.

# Summary
In this tutorial, we've explored how to combine LLMs with a Vector Database like MyScale to create a content recommendation system. Selecting the right vector database is very crucial for developing any efficient application. MyScale excels in handling vector data as well as structured metadata, ensuring fast and accurate query responses. Its ability to scale efficiently guarantees strong performance, even as datasets expand. With advanced indexing and querying features, MyScale significantly improves the performance and accuracy of your application.
Do you have any plans to build an AI application with MyScale? Join us to share your thoughts on Twitter (opens new window) and Discord (opens new window).



